-
Claude Design by Anthropic Labs 소개
Product Apr 17, 2026 Introducing Claude Design by Anthropic Labs Today, we’re launching Claude Design, a new Anthropic Labs product that lets you collaborate with Claude to create polished visual work like designs, prototypes, slides, one-pagers, and more.
-

비동기 에이전트의 시대 — Cognition의 Walden Yan & OpenInspect의 Cole Murray
The Age of Async Agents — Cognition's Walden Yan & OpenInspect's Cole Murray
80% Devin Commits, Spec-to-PR Workflows, Full VMs, Agent Memory, and PMs Shipping Code
-
Anthropic, 이탈리아 기업·연구·개발자 지원을 위해 밀라노 사무실 개설
May 27, 2026 Announcements Anthropic opens Milan office to support Italian enterprise, research, and developers
-

Endava가 Codex로 에이전틱 조직을 구축하는 방법
How Endava builds an agentic organization with Codex | OpenAI
Learn how Endava uses Codex to build an agentic organization, accelerating software delivery and reducing requirements analysis from weeks to hours.
-
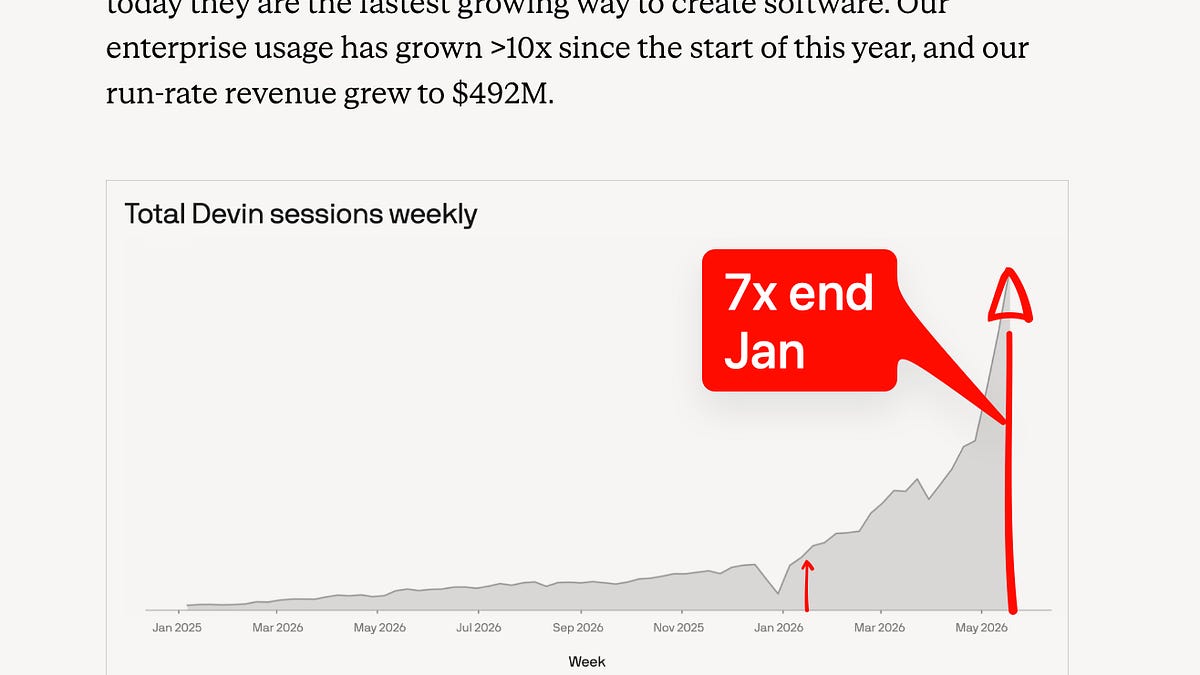
[AINews] Cognition이 $26B 시리즈 D 펀딩라운드에서 $1B 조달
[AINews] Cognition raises $1B in $26B Series D
coding is an uncapped TAM market
-

MUFG, OpenAI와 함께 AI 네이티브 조직으로 전환 목표
MUFG aims to become AI-native with OpenAI | OpenAI
MUFG uses ChatGPT Enterprise to build an AI-native organization, improve workflows, and deliver new AI-powered financial services at scale.
-

OpenAI의 최첨단 거버넌스 프레임워크
OpenAI’s Frontier Governance Framework | OpenAI
Explore OpenAI’s Frontier Governance Framework and how our AI safety, security, and risk practices align with emerging EU and California regulations.
-

Claude Opus 4.8 소개
Introducing Claude Opus 4.8 Product May 28, 2026 An upgrade to our Opus class of models, with stronger performance across coding, agentic tasks, and professional work, and the consistency to handle long-running work.
-

🔬 ESMFold2: 단백질에 대한 쓴 교훈이 온다 - 알렉스 라이브스, 바이오허브
🔬 ESMFold2: The Bitter Lesson is Coming for Proteins - Alex Rives, BioHub
Biohub’s Protein World Model: ESMC-6B, ESMFold2, 6.8B proteins, 1.1B structures, antibody design, SAEs, & the potential for programmable biology
-

Codex를 활용한 자체 개선 세금 에이전트 구축
Building self-improving tax agents with Codex | OpenAI
See how OpenAI, Thrive, and Crete built a self-improving tax agent with Codex, automating filings, improving accuracy, and accelerating workflows.
-
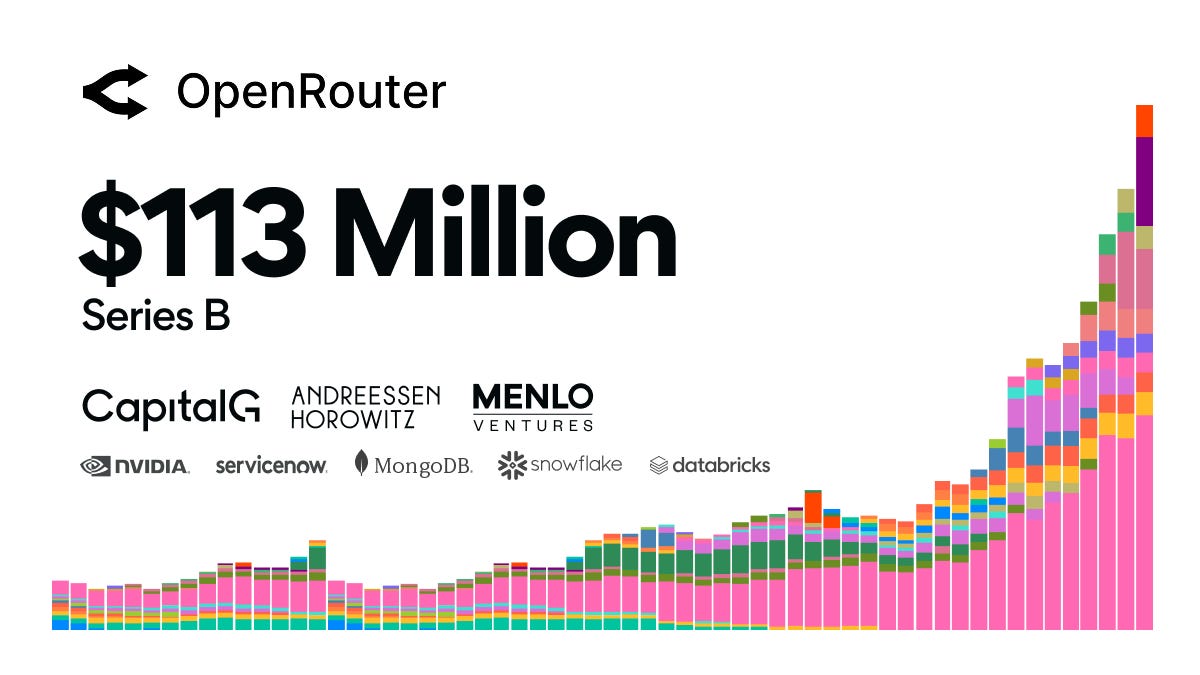
[AINews] 새로운 AI 인프라 데카콘들: Fireworks, Baseten (OpenRouter도 곧 나온다)
[AINews] New AI Infra decacorns: Fireworks, Baseten (with OpenRouter on the way)
it's funding news, but it's good news.
-
2026년 5월 27일 경제 연구 - 사회과학의 코딩 에이전트
Coding agents in the social sciences
-

2026년 선거 정보 및 보안조치
Election information and safeguards in 2026 | OpenAI
Ahead of global elections, we’re helping people access information, supporting cyber defenders, and increasing AI transparency
-

Warp의 GPT-5.5 기반 오픈소스 구축 전략
Warp’s big bet on building open source with GPT-5.5 | OpenAI
Warp uses GPT-5.5 and OpenAI models to coordinate coding agents across local, cloud, and open-source development workflows.
-
Anthropic, 서울 오피스 개설 앞두고 KiYoung Choi를 한국 대표이사로 임명
May 26, 2026 Announcements Anthropic appoints KiYoung Choi as Representative Director of Korea ahead of Seoul office opening
-

Import AI 458: 미래와의 대면; 그리고 특이점 이야기
Import AI 458: Reckoning with the future; and a singularity story
What AI-driven miracles will happen this year?
-

OpenAI, Grupo Folha, Grupo UOL 전략적 콘텐츠 파트너십 발표
OpenAI, Grupo Folha, and Grupo UOL announce strategic content partnership | OpenAI
OpenAI partners with Grupo Folha and Grupo UOL to bring trusted Brazilian journalism to ChatGPT, expanding access to news with attribution and transparency.
-
모든 모델 랩이 에이전트 랩으로 변하다
[AINews] All Model Labs are now Agent Labs - Latent.Space
a quiet day lets us tie together a few quotes as all model labs become agent labs
-
[AINews] 새로운 AI 인프라 유니콘들: Exa, Modal, TurboPuffer
[AINews] New AI Infra unicorns: Exa, Modal, TurboPuffer
a quiet day lets us feature fundraises!
-

글래스윙 프로젝트: 첫 업데이트 (2026년 5월 22일 공지)
Project Glasswing: An initial update
-

OpenAI가 Gartner 엔터프라이즈 코딩 에이전트 분야 리더로 선정
OpenAI named a Leader in enterprise coding agents by Gartner | OpenAI
OpenAI is named a leader in the 2026 Gartner Magic Quadrant for Enterprise AI Coding Agents, with Codex recognized for innovation and enterprise-scale deployment.
-

버진 애틀란틱이 코덱스로 더 빠르게 배포하는 방법
How Virgin Atlantic ships faster with Codex | OpenAI
How Virgin Atlantic used Codex to ship its revamped mobile app on a fixed holiday travel deadline, reaching near-total unit test coverage and zero P1 defects.
-

에이전트에게 컴퓨터를 제공하다 — Ivan Burazin, Daytona
Giving Agents Computers — Ivan Burazin, Daytona
We chat with Daytona's CEO about their insane 74% MoM Growth, 850K Daily Runs, Bare Metal Sandboxes, RL Evals, and the New Agent Cloud
-

어드벤트헬스, OpenAI와 함께 전인적 치료 선진화
AdventHealth advances whole-person care with OpenAI | OpenAI
AdventHealth is using ChatGPT for Healthcare to streamline workflows, reduce administrative burden, and return more time to patient care.
-
[AI뉴스] OpenAI GPT-next, 80년 된 Erdős 평면 단위 거리 추측을 1000달러 미만으로 증명
[AINews] OpenAI GPT-next disproves 80 year old Erdős planar unit distance problem for under $1000
a quiet day but a nice result in AI x mathematics
-

레일웨이: 에이전트-네이티브 클라우드 — 제이크 쿠퍼
Railway: The Agent-Native Cloud — Jake Cooper
3M Users, 100K Signups/Week, Own-Metal Data Centers, $200K+ Coding Agent Spend, and the Death of PRs
-
[AINews] Google I/O 2026: Gemini 3.5 Flash, Omni (비디오용 NanoBanana), Spark (백그라운드 에이전트), Antigravity 2.0
[AINews] Google I/O 2026: Gemini 3.5 Flash, Omni (NanoBanana for Video), Spark (background agents), and Antigravity 2.0
Google has been busy!
-

OpenAI의 국가 교육 프로젝트 차기 단계
The next phase of OpenAI’s Education for Countries | OpenAI
OpenAI advances Education for Countries, expanding AI adoption in schools with new partnerships, teacher training, and tools to improve global learning outcomes.
-

OpenAI 모델이 이산 기하학의 중심 추측을 반박했다
An OpenAI model has disproved a central conjecture in discrete geometry | OpenAI
An OpenAI model solved the 80-year-old unit distance problem, disproving a major conjecture in discrete geometry and marking a milestone in AI-driven mathematics.
-

Ramp 엔지니어들이 Codex로 코드 리뷰를 가속화하는 방법
How Ramp engineers accelerate code review with Codex | OpenAI
How Ramp engineers use Codex with GPT-5.5 to review code and ship improvements, allowing them to get substantive feedback in minutes instead of hours.
