-

AGI를 향한 진전 측정: 인지 프레임워크
Measuring Progress Towards AGI: A Cognitive Framework
We’re introducing a framework to measure progress toward AGI, and launching a Kaggle hackathon to build the relevant evaluations.
-
AlphaGo 10주년: AI 혁신이 AGI로의 길을 열어가는 방법 – Google DeepMind
AlphaGo at 10: How AI Innovation Is Paving the Path to AGI â Google DeepMind
Ten years since AlphaGo, we explore how it is catalyzing scientific discovery and paving a path to AGI.
-

Gemini 3.1 Pro: 가장 복잡한 작업을 위한 더 똑똑한 모델
Gemini 3.1 Pro: A smarter model for your most complex tasks
3.1 Pro is designed for tasks where a simple answer isn’t enough.
-
구글 딥마인드의 인도 파트너십: 과학과 교육에서의 AI 규모 확대
Google DeepMind Partnerships in India: scaling AI in science and education â Google DeepMind
Google DeepMind brings National Partnerships for AI initiative to India, scaling AI for science and education
-
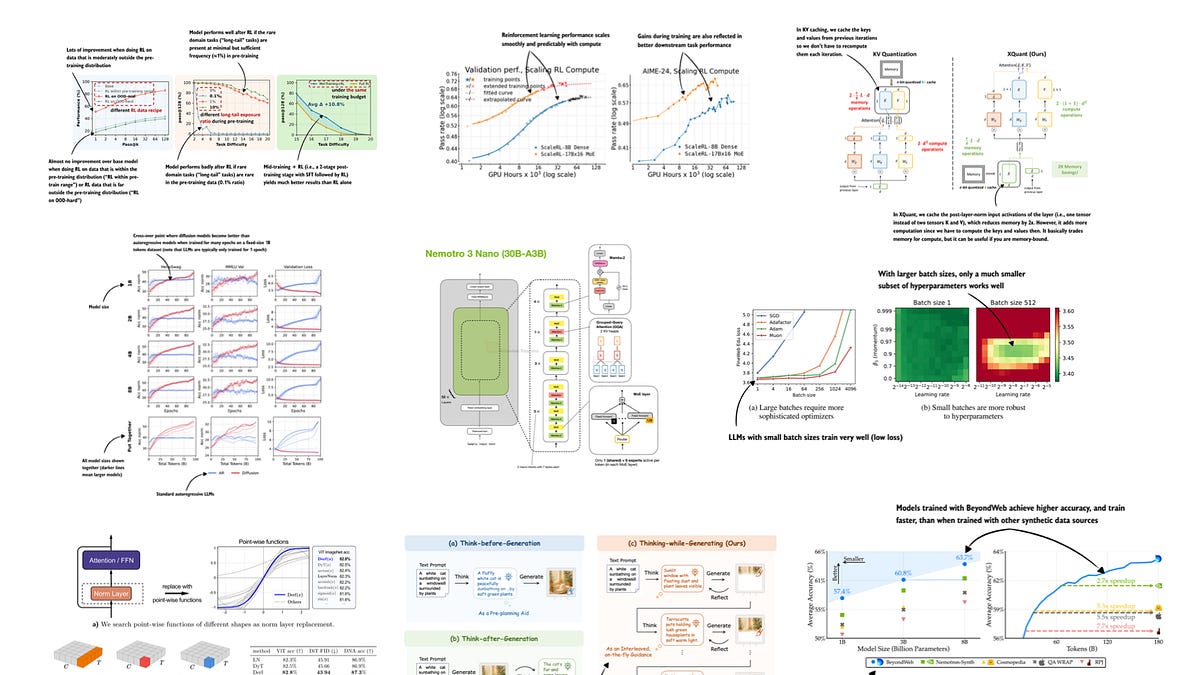
LLM 연구논문: 2025년 목록 (7월~12월)
LLM Research Papers: The 2025 List (July to December)
In June, I shared a bonus article with my curated and bookmarked research paper lists to the paid subscribers who make this Substack possible.
-

세 가지 간단한 단계로 제품 평가하기
Product Evals in Three Simple Steps
Label some data, align LLM-evaluators, and run the eval harness with each change.
-
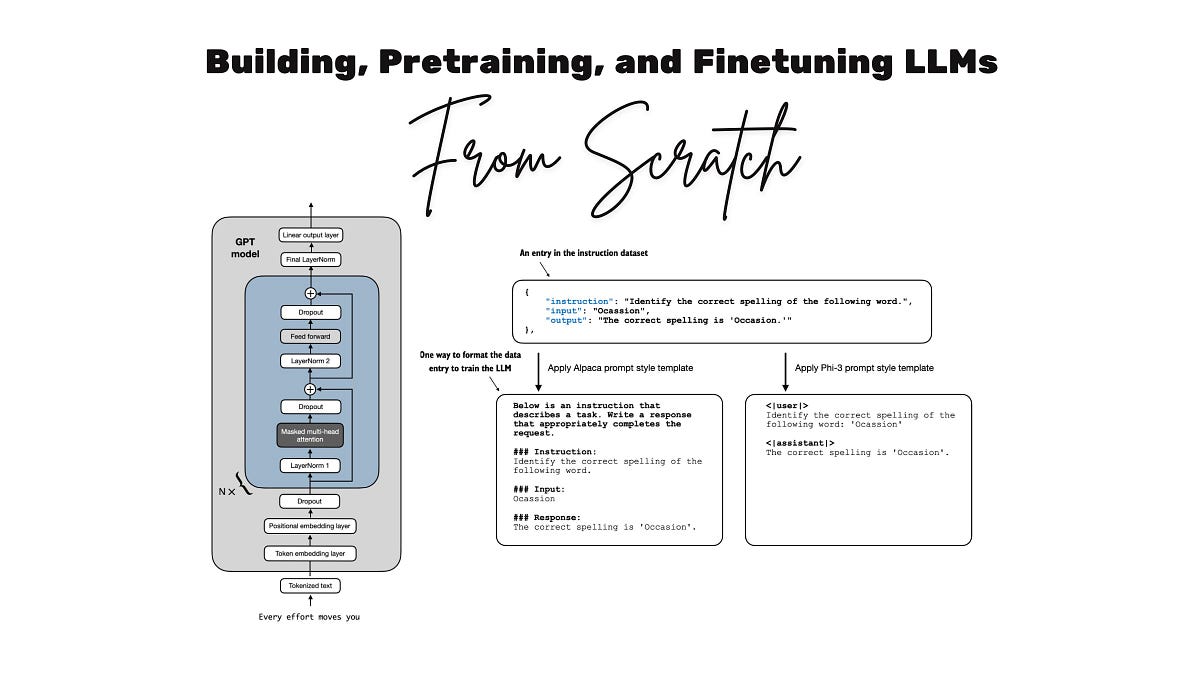
바닥부터 배우는 LLM 코딩: 완전한 강의
Coding LLMs from the Ground Up: A Complete Course
Why build LLMs from scratch? It's probably the best and most efficient way to learn how LLMs really work. Plus, many readers have told me they had a lot of fun doing it.
-

LLM 추론을 위한 강화학습의 현황
The State of Reinforcement Learning for LLM Reasoning
Understanding GRPO and New Insights from Reasoning Model Papers
-
NVIDIA GTC 2025 - LLM 기반 애플리케이션 구축
NVIDIA GTC 2025 - Building LLM-Powered Applications
Chip Huyen and I share what we've learned, best practices, and insights at NVIDIA GTC 2025.
-
ML 시스템 구축, 확장, 실행 등의 39가지 교훈
39 Lessons on Building ML Systems, Scaling, Execution, and More
ML systems, production & scaling, execution & collaboration, building for users, conference etiquette.
-

Weights & Biases LLM 평가기 해커톤 - 해커톤 심사위원
Weights & Biases LLM-Evaluator Hackathon - Hackathon Judge
Being a human judge at the Weights & Biases LLM-as-a-Judge Hackathon
-

ML/AI 엔지니어 면접 및 채용하는 방법
How to Interview and Hire ML/AI Engineers
What to interview for, how to structure the phone screen, interview loop, and debrief, and a few tips.
-
LLM으로 1년간 구축하며 배운 것들
What We've Learned From A Year of Building with LLMs
From the tactical nuts & bolts to the operational day-to-day to the long-term business strategy.
-
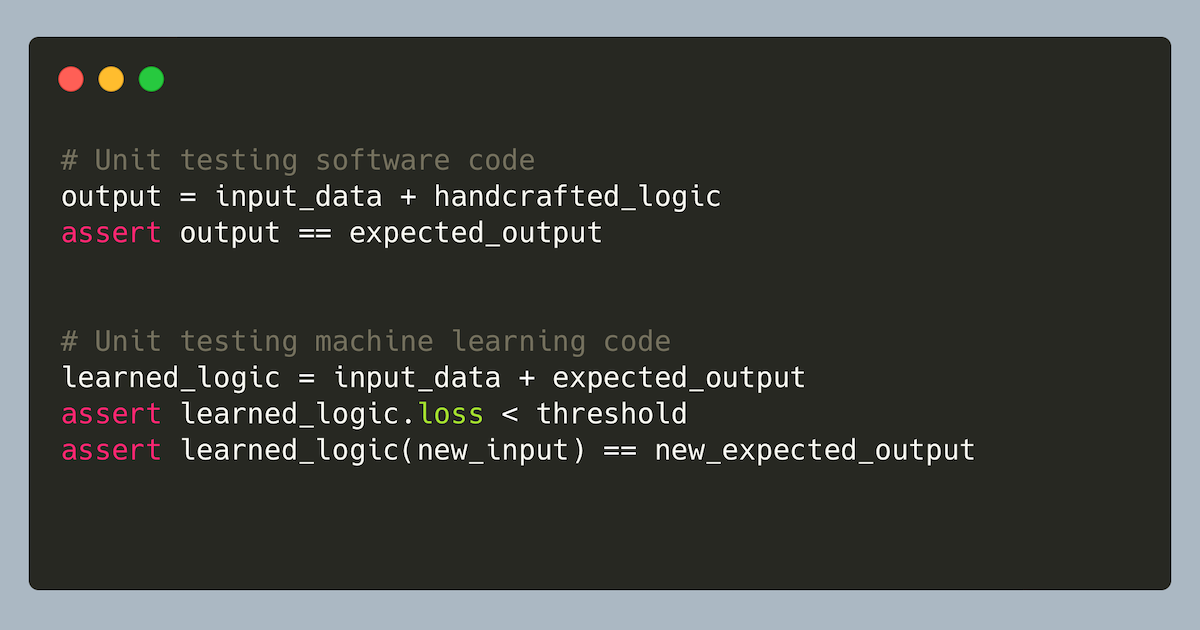
머신러닝 모델을 단위 테스트에서 모킹하지 마세요
Don't Mock Machine Learning Models In Unit Tests
How unit testing machine learning code differs from typical software practices
-
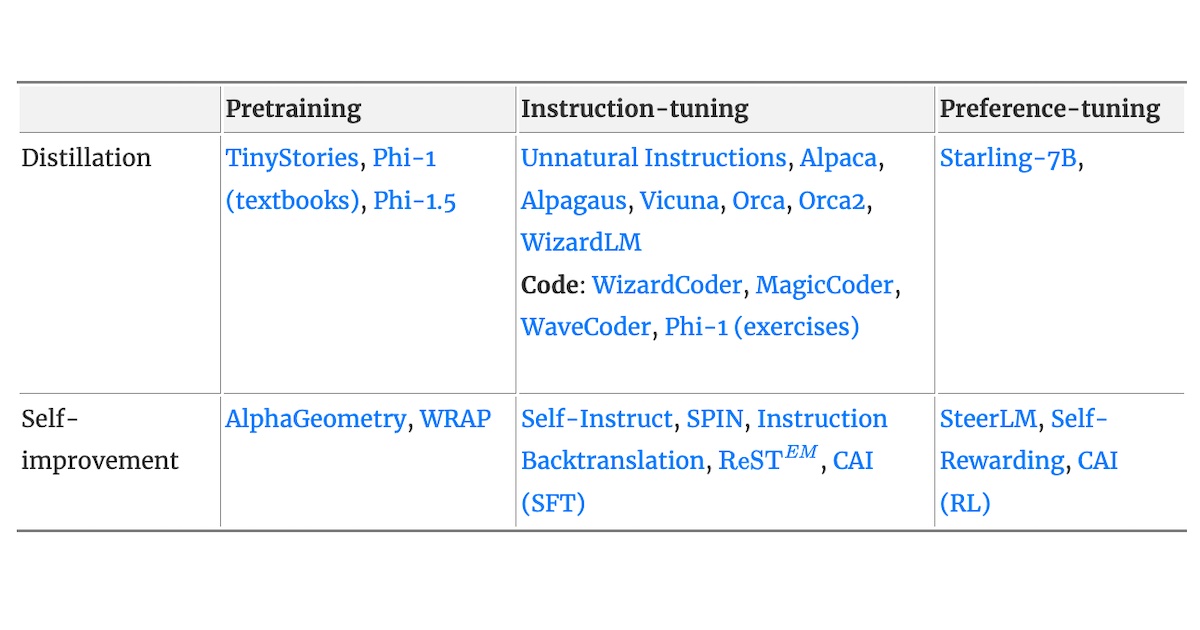
파인튜닝을 위한 합성 데이터 생성 및 활용 방법
How to Generate and Use Synthetic Data for Finetuning
Overcoming the bottleneck of human annotations in instruction-tuning, preference-tuning, and pretraining.
-

언어 모델링 논문 목록 (논문 클럽 시작하기)
Language Modeling Reading List (to Start Your Paper Club)
Some fundamental papers and a one-sentence summary for each; start your own paper club!
-

Claude 3.5 Sonnet으로 SWE-bench Verified의 기준을 높이다
Raising the bar on SWE-bench Verified with Claude 3.5 Sonnet Jan 06, 2025
-

앤스로픽의 경제 연구
Economic Research \ Anthropic
-
2026년 5월 25일 공지사항: Anthropic 공동창업자 크리스 올라의 교황 레오 14세 회칙 '매그니피카 후마니타스'에 대한 발언
May 25, 2026 Announcements Anthropic co-founder Chris Olah's remarks on Pope Leo XIV's encyclical "Magnifica humanitas"

