-
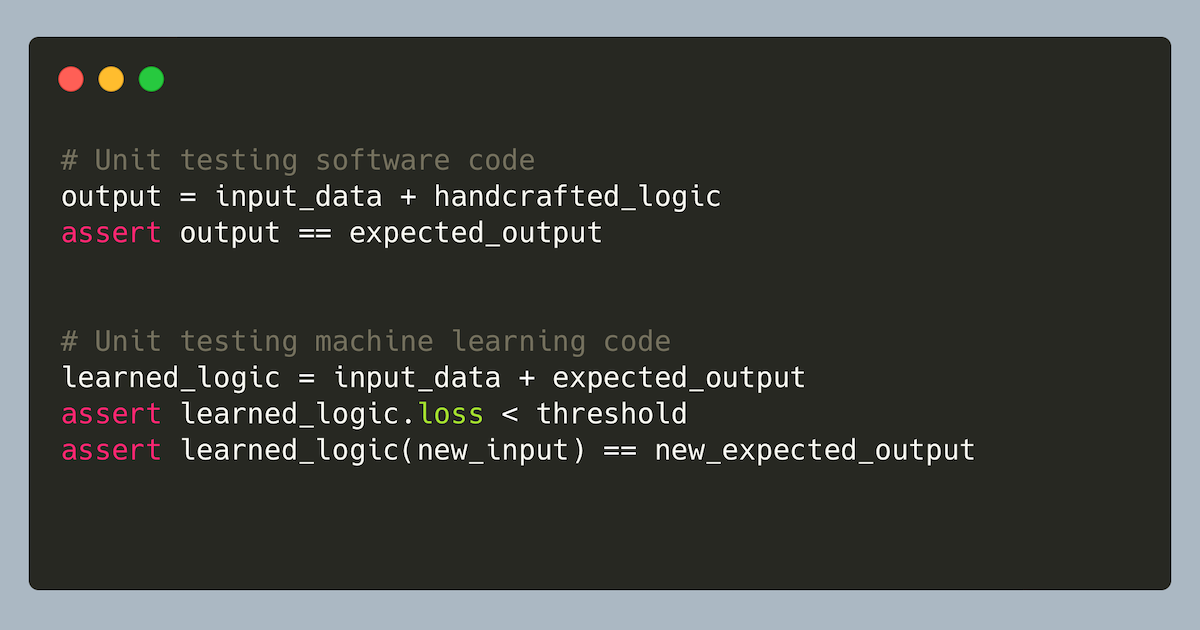
머신러닝 모델을 단위 테스트에서 모킹하지 마세요
Don't Mock Machine Learning Models In Unit Tests
How unit testing machine learning code differs from typical software practices
-
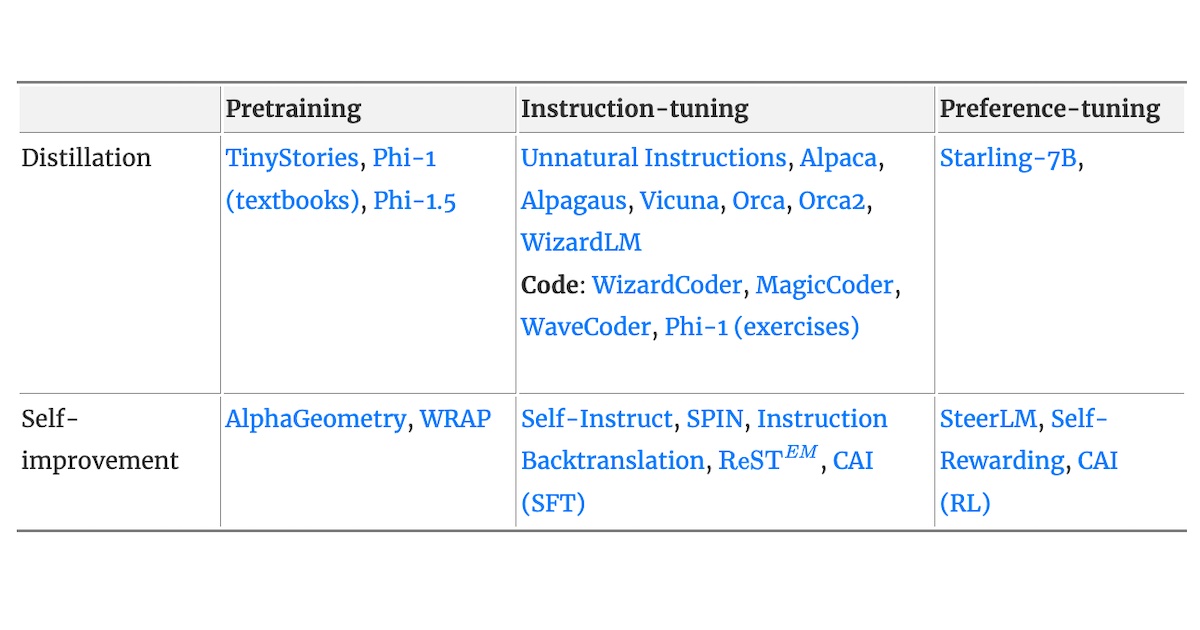
파인튜닝을 위한 합성 데이터 생성 및 활용 방법
How to Generate and Use Synthetic Data for Finetuning
Overcoming the bottleneck of human annotations in instruction-tuning, preference-tuning, and pretraining.
-

언어 모델링 논문 목록 (논문 클럽 시작하기)
Language Modeling Reading List (to Start Your Paper Club)
Some fundamental papers and a one-sentence summary for each; start your own paper club!
-

2023년 연간 회고
2023 Year in Review
An expanded charter, lots of writing and speaking, and finally learning to snowboard.
-
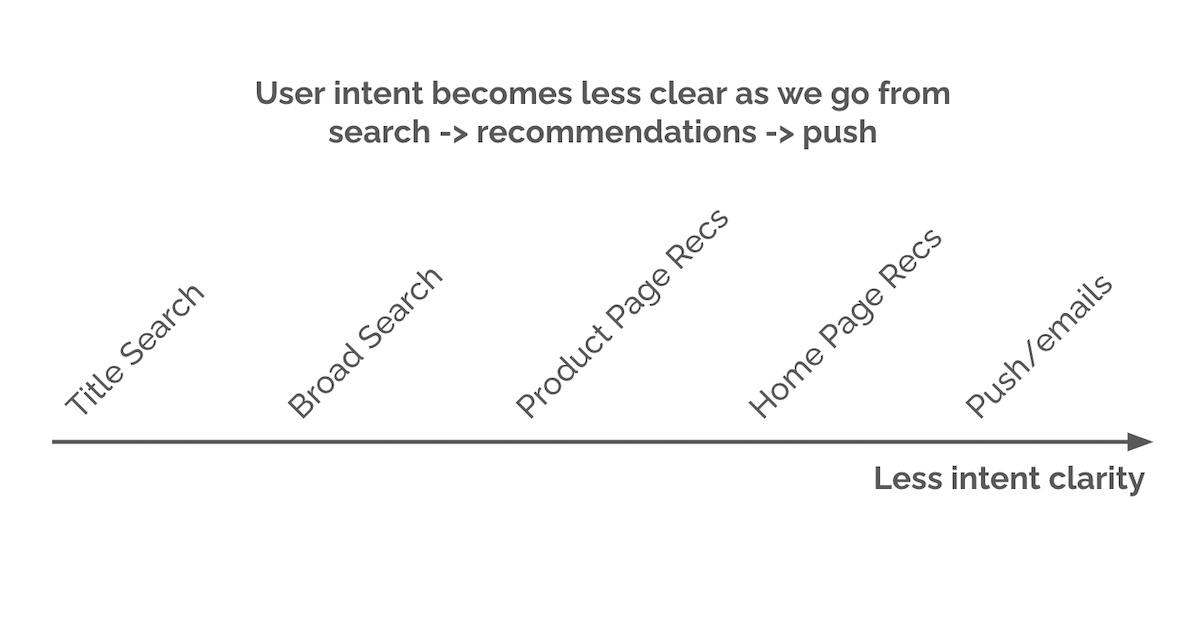
푸시 알림: 무엇을 보내고, 무엇을 피하고, 얼마나 자주 보낼지
Push Notifications: What to Push, What Not to Push, and How Often
Sending helpful & engaging pushes, filtering annoying pushes, and finding the frequency sweet spot.
-
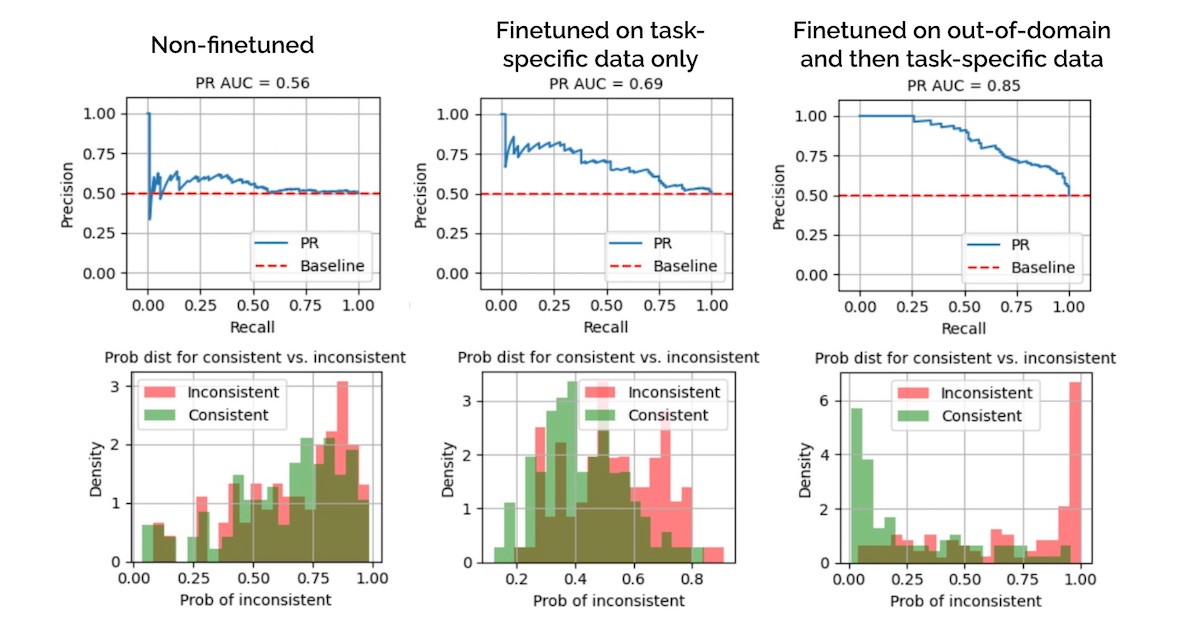
도메인 외 파인튜닝을 통한 환각 탐지 부트스트래핑
Out-of-Domain Finetuning to Bootstrap Hallucination Detection
How to use open-source, permissive-use data and collect less labeled samples for our tasks.
-

2023 AI 엔지니어 서밋 회고
Reflections on AI Engineer Summit 2023
The biggest deployment challenges, backward compatibility, multi-modality, and SF work ethic.
-

AI 엔지니어 2023 기조 연설 - LLM 시스템을 위한 빌딩 블록
AI Engineer 2023 Keynote - Building Blocks for LLM Systems
Evals, retrieval-augmented generation, guardrails, and collecting feedback; all that good stuff.
-

생성형 요약의 평가 및 환각 탐지
Evaluation & Hallucination Detection for Abstractive Summaries
Reference, context, and preference-based metrics, self-consistency, and catching hallucinations.
-

LLM 패턴을 문제에 맞추는 방법
How to Match LLM Patterns to Problems
Distinguishing problems with external vs. internal LLMs, and data vs non-data patterns