-

세 가지 간단한 단계로 제품 평가하기
Product Evals in Three Simple Steps
Label some data, align LLM-evaluators, and run the eval harness with each change.
-
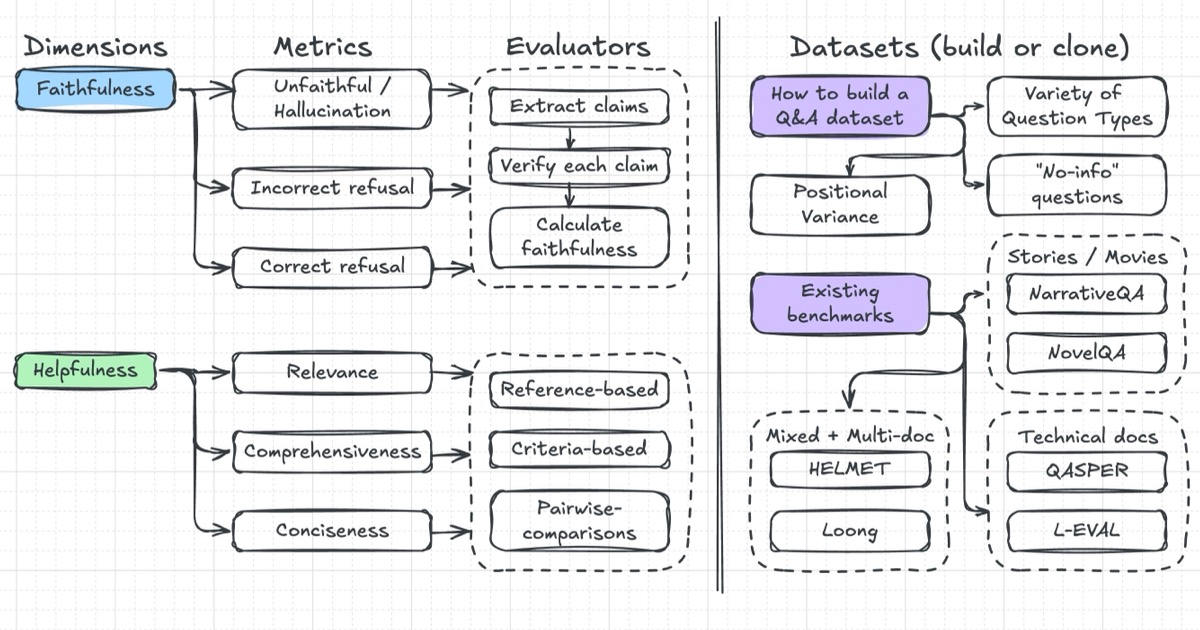
긴 맥락 질의응답 시스템 평가
Evaluating Long-Context Question & Answer Systems
Evaluation metrics, how to build eval datasets, eval methodology, and a review of several benchmarks.
-
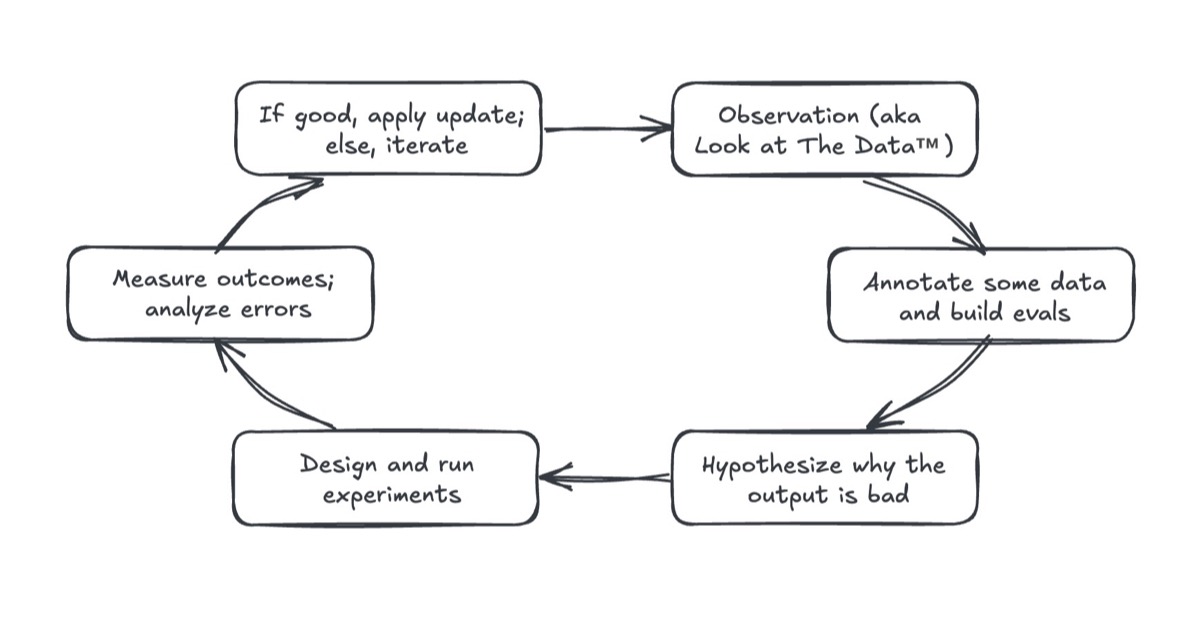
LLM-as-Judge는 제품을 구하지 못합니다—프로세스 개선이 핵심입니다
An LLM-as-Judge Won't Save The Product—Fixing Your Process Will
Applying the scientific method, building via eval-driven development, and monitoring AI output.
-
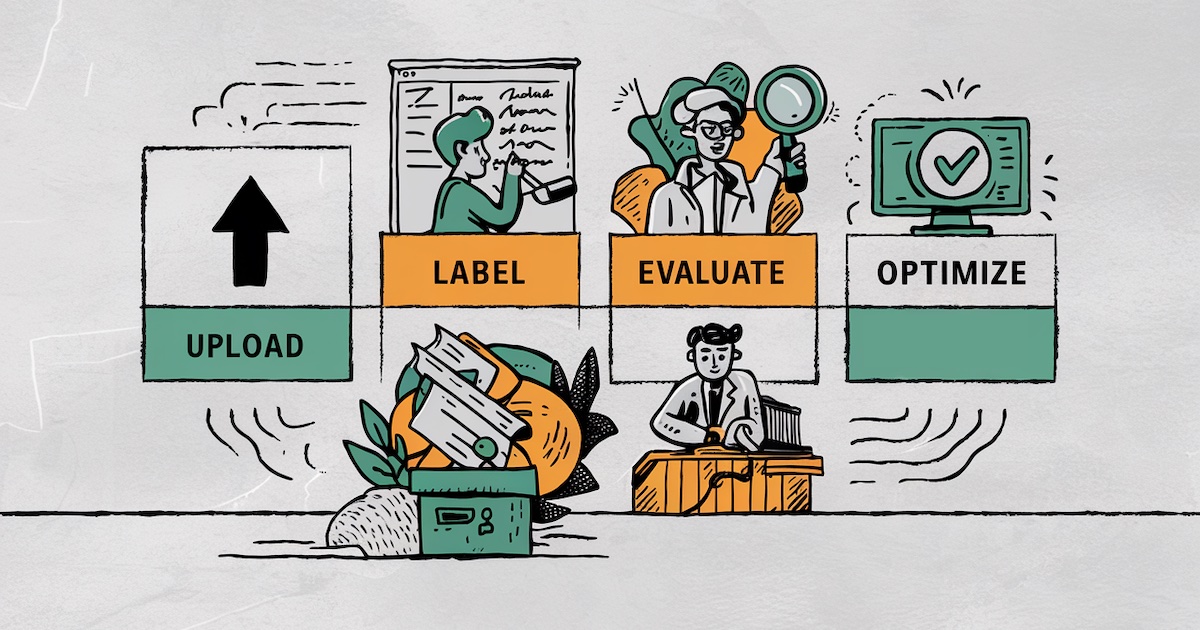
AlignEval: 평가를 쉽고 재미있으며 자동화되게 만드는 앱 구축하기
AlignEval: Building an App to Make Evals Easy, Fun, and Automated
Look at and label your data, build and evaluate your LLM-evaluator, and optimize it against your labels.
-

Weights & Biases LLM 평가기 해커톤 - 해커톤 심사위원
Weights & Biases LLM-Evaluator Hackathon - Hackathon Judge
Being a human judge at the Weights & Biases LLM-as-a-Judge Hackathon
-
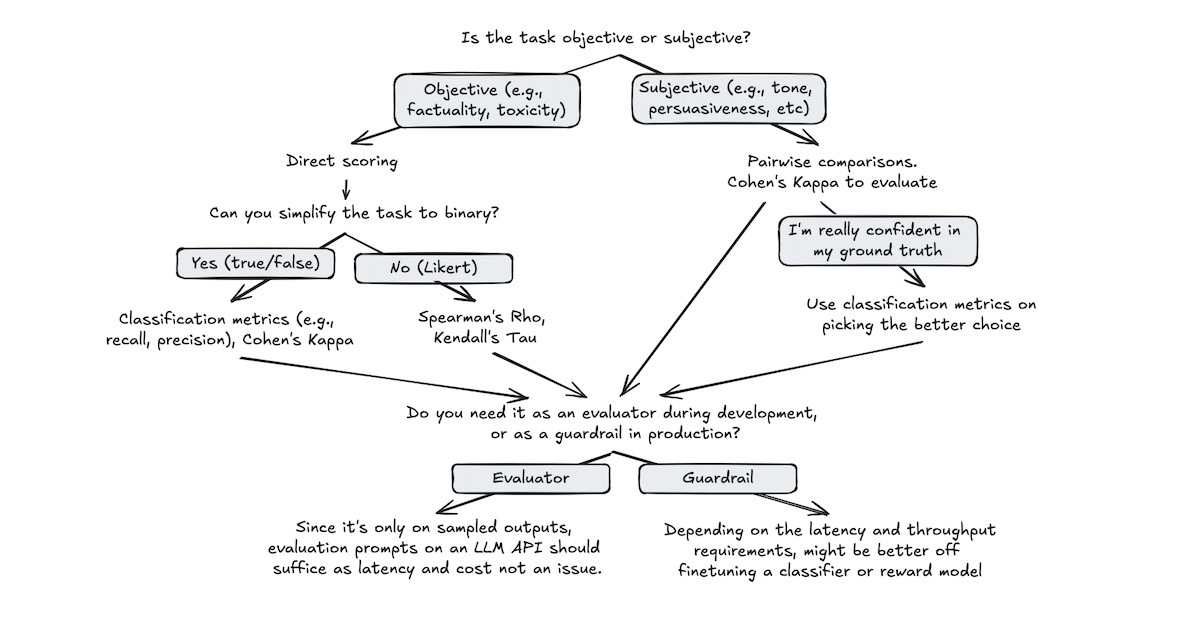
LLM 평가자의 효율성 평가 (LLM-as-Judge)
Evaluating the Effectiveness of LLM-Evaluators (aka LLM-as-Judge)
Use cases, techniques, alignment, finetuning, and critiques against LLM-evaluators.
-

작동하고 작동하지 않는 작업별 LLM 평가
Task-Specific LLM Evals that Do & Don't Work
Evals for classification, summarization, translation, copyright regurgitation, and toxicity.