-
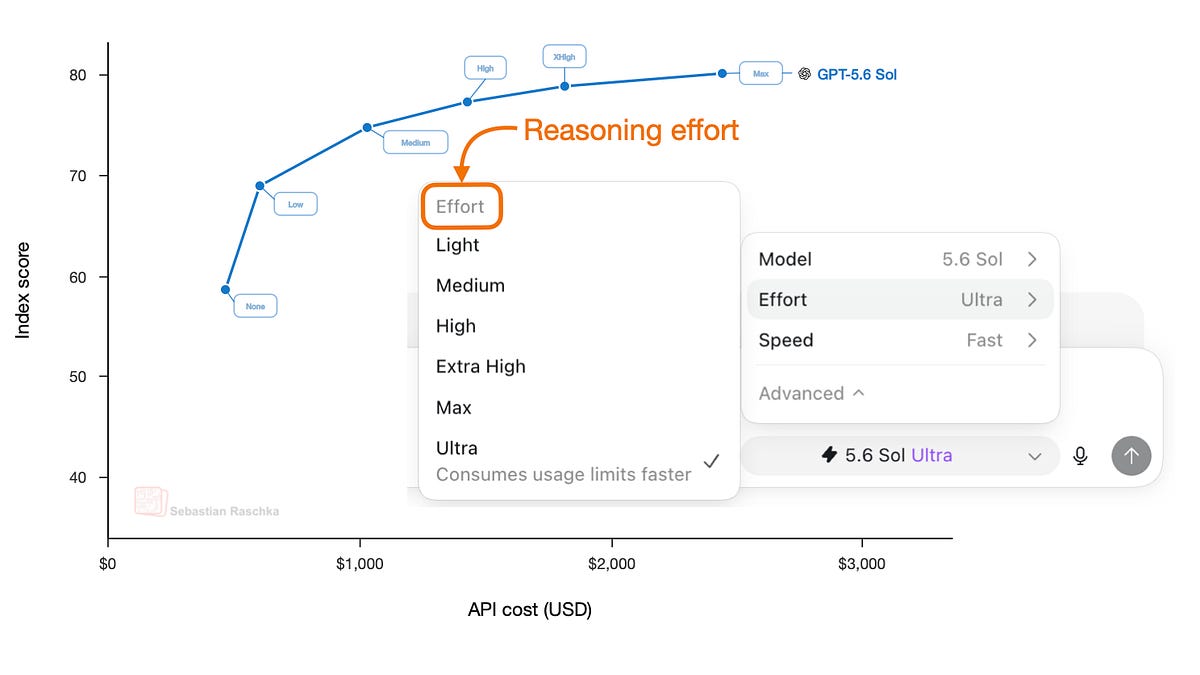
LLM에서 추론 노력 제어하기
Controlling Reasoning Effort in LLMs
How LLMs Learn Low-, Medium-, and High-Effort Reasoning Modes
-
로컬 LLM 실행에 관한 모든 것
GitHub - jamesob/local-llm: Everything I know about running LLMs locally
<p>Article URL: <a href="https://github.com/jamesob/local-llm">https://github.com/jamesob/local-llm</a></p> <p>Comments URL: <a href="https://news.ycombinator.com/item?id=48775921"…