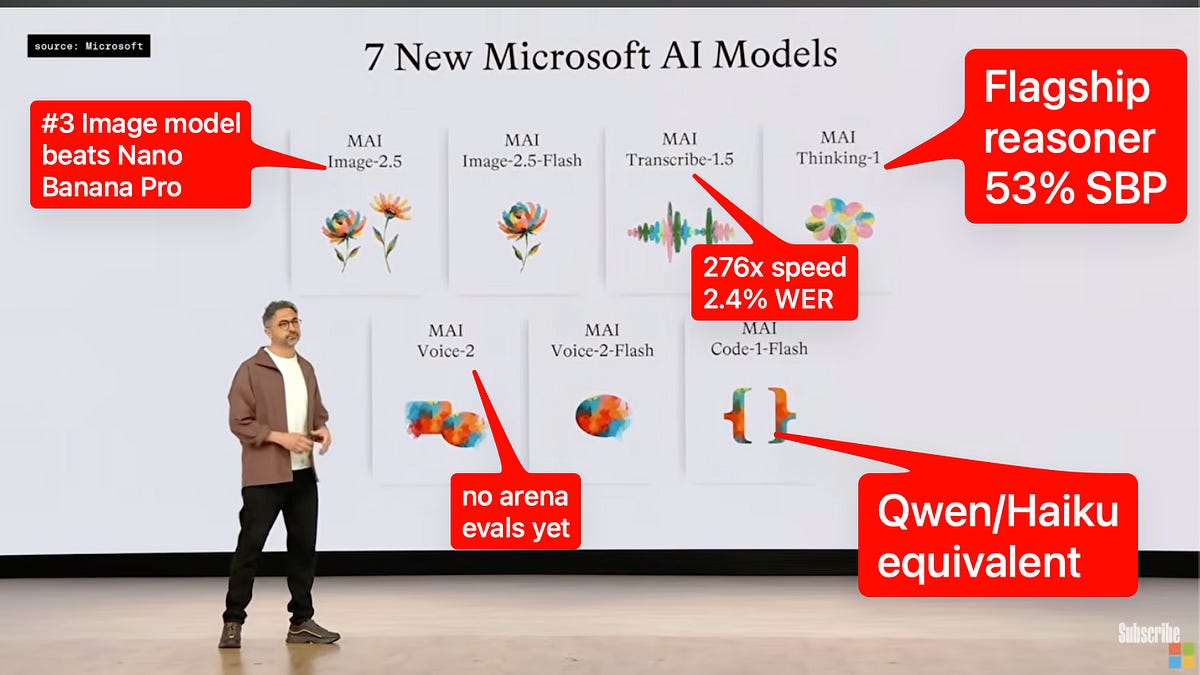
Today was a big day, not least because we caught up on the state of GitHub vs Agents, and recorded a special pod with No Priors and Satya Nadella — at MS Build, Satya and Mustafa announced 7 new MAI models:
This is an impressive lineup, especially considering that the Microsoft-Inflection deal that set up MAI only happened 2 years ago, and that these are all from-scratch pretrains. MAI today is by no means an unqualified frontier lab, but it is a good tier 2 neolab with obvious incentives to support domain specific finetunes (as opposed to the frontier labs who have ~all killed finetuning).
The star of the show was the 100+ page MAI tech report, which the research community is giving glowing reviews:
[microsoft MAI tech report is a gold mine, one of the most transparent for a model at this scale. this model uses zero synthetic data or distillation from previous models. this means reasoning, agentic behavior, tool use are all learned fully during post-training with no cold
Mustafa Suleyman @mustafasuleyman
Super excited to announce seven new world-class MAI models today. They represent what we consider a new era in AI designed to keep you in control and on the frontier. First is our text foundation model, MAI-Thinking-1, exceptionally strong on reasoning and SWE tasks. - It’s a
12:18 AM · Jun 3, 2026 · 53.7K Views
14 Replies · 81 Reposts · 685 Likes](https://x.com/eliebakouch/status/2061965825037254947)
You can catch up on all the rest of the announcement in the excellent Verge recap, and the tweet summaries below:
AI News for 06/1/2026-6/2/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
Top Story: Microsoft Build recap, and new MAI model technical details
Microsoft used Build to position itself as both an AI platform company and a frontier-model lab, pairing broad product launches with unusually detailed disclosures about its new MAI model family.
- Microsoft AI announced seven new MAI models spanning reasoning, code, image, speech transcription, and voice, led by MAI-Thinking-1, MAI-Code-1-Flash, MAI-Image-2.5, MAI-Transcribe-1.5, and MAI-Voice-2 according to @MicrosoftAI and @mustafasuleyman
- The flagship reasoning model MAI-Thinking-1 was presented as Microsoft’s first reasoning model, built with clean data lineage and zero distillation from third-party models in posts from @mustafasuleyman, @baseten, @tuhinone, and @HannaHajishirzi
- Microsoft released a 109-page technical report for MAI-Thinking-1, which drew strong positive reactions from technically oriented readers for its level of transparency, including @eliebakouch, @ethanCaballero, @nrehiew_, @yacinelearning, and @stochasticchasm
- Microsoft also emphasized local AI and agent-native Windows: Build messaging highlighted secure execution layers for agents, a new Surface RTX Spark Dev Box, Windows AI access to the broader Windows GPU install base, and concept hardware such as Project Solara/Scout, summarized by @yusuf_i_mehdi, @TheTuringPost, @kimmonismus, and @kimmonismus
- Build also included a major GitHub Copilot app push as the “desktop home for agent-native software development,” with canvases, cross-device continuity, and tighter GitHub agent workflows, from @pierceboggan, @lukehoban, and reactions from @techgirl1908
- Microsoft introduced Web IQ, a new grounding/search API stack for AI agents, claiming the APIs already power “nearly all AI agents and chatbots in the industry today, including Copilot and ChatGPT,” via @JordiRib1
-
Satya Nadella framed Build as an ecosystem moment rather than a single-product launch, while Mustafa Suleyman framed it as the output of Microsoft’s internal “hill-climbing machine,” in @satyanadella, @mustafasuleyman, and reaction from @nrehiew_
-
Microsoft described MAI-Thinking-1 as a 35B active parameter MoE with a 256K context window in @mustafasuleyman
- A separate summary from @scaling01 says the model is a 1T@35B parameter model, pre-trained on 30T tokens, and trained using 8192 GB200 GPUs; this appears to be a reading of the technical report rather than Microsoft marketing copy
- @kimmonismus similarly summarized it as a mid-size MoE with 45B active params, but this conflicts with Mustafa’s own 35B active figure; the more authoritative figure in the tweet set is the official 35B active number
- Microsoft claims 97% on AIME 2025 and 53% on SWE-Bench Pro, with blind human raters on Surge preferring it overall to Sonnet 4.6, from @mustafasuleyman and @asadovsky
- Microsoft says the model is optimized on MAIA 200, with 30% better performance per dollar and 1.4x performance-per-watt gain versus GB200 when running MAI models end-to-end, per @mustafasuleyman
-
Microsoft and partners repeatedly stressed no third-party distillation, “clean data lineage,” and enterprise-controlled fine-tuning with “100% eyes-off” post-training data through Baseten, in @baseten, @tuhinone, and @MicrosoftAI
-
Microsoft introduced MAI-Code-1-Flash as a fast coding model for VS Code and GitHub Copilot CLI, first announced by @pierceboggan and later highlighted by @mariorod1
- Official Microsoft messaging via @mustafasuleyman says Code-1-Flash achieves 51% on SWE-Bench Pro despite having just 5B parameters, positioning it near Haiku-class size/cost
- A competing summary from @scaling01 describes it as a 137B parameter MoE, 256K context, trained on 10T+ tokens, and “stronger and more efficient than Claude 4.5 Haiku.” That likely indicates 5B active parameters rather than total parameters; the tweets do not fully reconcile this distinction, but together imply small active footprint within a much larger MoE
-
Availability at launch was highlighted as GitHub Copilot / VS Code-first, per @scaling01 and @mariorod1
-
Microsoft launched MAI-Image-2.5 and a Flash variant, claiming both reached #2 on leaderboards, with @mustafasuleyman saying they surpass Nano Banana 2 on image editing
- Independent leaderboard accounts supported the high ranking: @arena reported #2 in Image Edit Arena with score 1401, +10 points over Nano Banana 2, Grok Imagine, and ChatGPT Image Latest HF
- @arena further said MAI-Image-2.5 “advances the Pareto frontier,” meaning no model at its price tier scores higher on that benchmark
-
Distribution partners quickly followed, including @OpenRouter and @fal
-
@ArtificialAnlys reported MAI-Transcribe-1.5 as an unusually strong speed/accuracy point on the STT frontier: ~276x realtime, 2.4% AA-WER, #3 overall on its leaderboard
- The model supports 43 languages, including English, French, Arabic, Japanese, and Chinese, and supports keyword biasing for rarer terms such as names and medical terminology, per @ArtificialAnlys
- Pricing was reported as $6 per 1,000 minutes of audio via Microsoft Foundry in @ArtificialAnlys
-
OpenRouter also listed the model among the three MAI launches it brought live the same day in @OpenRouter
-
MAI-Voice-2 appears in Microsoft’s “seven models” umbrella and in OpenRouter’s availability post at @OpenRouter
-
The tweet set contains little technical detail on Voice-2 itself beyond launch/availability
-
The dominant technical reaction was that Microsoft released an unusually detailed frontier-model report: @eliebakouch called it “one of the most transparent for a model at this scale,” @nrehiew_ said it “could really serve as an updated textbook for LLM training today,” and @stochasticchasm called it a “gold mine”
-
Multiple readers highlighted that the report disclosed pipeline details, scaling ladder methodology, data curation, infra metrics, and MFU numbers; this level of specificity is what drew praise from @ethanCaballero, @eliebakouch, and @nrehiew_
-
A major technical claim repeated across commentary is that MAI-Thinking-1 used no synthetic data and no distillation, not only in post-training but throughout the disclosed pipeline, from @eliebakouch, @stochasticchasm, and @HannaHajishirzi
- @eliebakouch says the report explicitly notes data from Common Crawl plus private sources, with targeted sub-pipelines for different domains, heavy extraction/dedup work, and an intentional choice of no synthetic data
-
The report’s internal private NLL set used for scaling decisions was summarized by @eliebakouch as:
-
50% code
- 17.5% STEM
- 17.5% math
- 10% general knowledge
- 5% multilingual
- @eliebakouch says architecture promotion in the scaling ladder was based on an Efficiency Gain (EG) metric: how much extra compute the baseline would need to match the candidate’s loss
-
The same thread notes ablations at roughly 100/200 tokens per parameter, described as around “Chinchilla optimal” for the setup, while also remarking this differs from dense-model heuristics due to MoE structure in @eliebakouch
-
The most discussed technical choice was that Microsoft appears to have started RL from a checkpoint with no prior reasoning exposure, which several readers found notable. @stochasticchasm called this a “very interesting decision,” while @stochasticchasm reacted to graphs suggesting a jump from <20% AIME25 to >95%
- @HannaHajishirzi described the “climbing from scratch” recipe as simple recipes, rigorous science, self-distillation, patience, and great infra
- @soldni characterized the process as “climbing with no distillation, like the big boys do”
-
Some independent readers inferred from the report that synth data remains very valuable for agentic performance in the broader field, even if Microsoft deliberately avoided it here; see @stochasticchasm
-
A detail that got substantial attention from the DSPy/late-interaction crowd: Microsoft reportedly used GEPA / DSPy-optimized LLM judges in pretraining data curation and quality scoring
-
This was highlighted by @bj2rn, @LakshyAAAgrawal, and @lateinteraction
-
Microsoft reportedly disclosed exact MFU across iterations, which multiple readers said is rarely shared at this scale, per @eliebakouch
- @scaling01 summarized the run as using 8192 GB200 GPUs
- @eliebakouch singled out a reported ~40% higher throughput per watt-type figure as “pretty impressive and bullish on microsoft chips,” though this may refer to rack-level budget or serving configuration and was not fully unpacked in-tweet
- Microsoft’s official framing connected model design to MAIA 200 custom silicon and emphasized better performance-per-dollar and performance-per-watt vs NVIDIA GB200 in @mustafasuleyman
- Build’s broader Windows/local-AI narrative also centered on hardware specifics such as:
-
Reactions also pointed to local runs of large models, e.g. @kimmonismus on RTX Spark running a 120B parameter model locally
-
GitHub unveiled the GitHub Copilot app, pitched as a desktop surface for agent-native software development by @pierceboggan
-
Key themes included:
-
canvases for bidirectional work between users and agents, per @Techmeme
- continuity across CLI, mobile, web, local, and cloud, per @lukehoban
- a growing role for GitHub as the center of agent workflows, reflected in @techgirl1908 and @OrenMe
-
Copilot CLI also got an experimental terminal UI with tabs, built-in feedback/rubber duck, prompt scheduling, and voice input, per @GHchangelog
-
Microsoft’s Windows org framed Build around “faster developer execution, a secure execution layer for agents, and unmetered intelligence that runs locally on device,” per @yusuf_i_mehdi
- Several posts stressed that Microsoft wants Windows to be the trusted execution platform for agents, not just Azure
- @TheTuringPost described Project Solara as a platform for agent-first devices, with concepts including:
- @kimmonismus saw these as handheld/desktop devices for controlling agents and compared them to expectations people had for standalone OpenAI hardware
-
@kimmonismus separately highlighted Microsoft Scout as an “always-on personal agent for work”
-
@JordiRib1 announced Microsoft Web IQ as a suite of AI-native grounding APIs for web pages, news, images, and videos
- His framing is important context: classic search engines were built for humans, but Microsoft believes future search demand will come from agents, potentially 1000x more queries than human search traffic
-
He claimed Web IQ was re-architected from Bing’s stack for quality, latency, and token efficiency, and that it already powers major chatbots including Copilot and ChatGPT
-
@jeffboudier said Satya cited 11,000+ models available in Microsoft Foundry, of which 10,928 come from Hugging Face
-
This supports Microsoft’s parallel identity at Build: both a first-party model builder and a large multi-model hosting/distribution platform
-
Several observers noted Build discussion around data center expansion, community backlash, and Microsoft’s argument that AI infra can expand without raising electricity costs to local communities; see @kimmonismus and @kimmonismus
- @scaling01 highlighted Mustafa saying AI compute will grow 1000x in the next 3 years, taking today’s rough 5e27 FLOPs frontier scale to 5e30 FLOPs by 2029
-
@mustafasuleyman summarized the company’s philosophical theme as “Humanist superintelligence”
-
Microsoft launched seven new MAI models at Build: @MicrosoftAI
- Official metrics for MAI-Thinking-1: 35B active MoE, 256K context, 97% AIME 2025, 53% SWE-Bench Pro, and blind human preference over Sonnet 4.6: @mustafasuleyman
- Official metrics for MAI-Code-1-Flash: 51% SWE-Bench Pro, 5B parameters as stated in tweet copy: @mustafasuleyman
- MAI-Image-2.5 ranking claims were independently echoed by @arena
- MAI-Transcribe-1.5 speed/accuracy details came from independent benchmark account @ArtificialAnlys
-
Microsoft released a 109-page technical report: @eliebakouch
-
“Microsoft is training serious models now?” from @teortaxesTex is an interpretive reaction to the model/report quality, not a standalone fact
- Claims that the report is “one of the most transparent” or “an updated textbook” are opinions from @eliebakouch and @nrehiew_, albeit shared by many readers
- @kimmonismus and @TheTuringPost framed Build as a strategic shift from cloud-only AI toward local reasoning/agents; that is analysis rather than official wording
-
Posts claiming Microsoft “leaked” Anthropic Mythos FLOPs, including @swyx and @scaling01, are speculative interpretations of a slide, later contested by the same cluster of commenters
-
Technical readers were broadly impressed by the report’s transparency and Microsoft’s willingness to publish details usually withheld at this scale: @eliebakouch, @nrehiew_, @ethanCaballero, @stochasticchasm
- Some saw MAI-Thinking-1 as proof Microsoft is becoming a genuine frontier lab rather than just a model reseller or application layer, e.g. @teortaxesTex, @echen, @NandoDF
-
Enterprise/platform supporters liked the clean-data-lineage, fine-tunable, eyes-off post-training data story, especially Baseten/Microsoft’s positioning around ownership and control: @baseten, @tuhinone
-
Several posts focused on reading and unpacking the report rather than cheering the launch, especially @stochasticchasm, @nrehiew_, and @eliebakouch
- Some commentators were careful on benchmark interpretation. @kimmonismus noted Microsoft appeared to compare to Sonnet 4.6 generally, with Opus-level comparability only on SWE Pro
-
@iScienceLuvr specifically appreciated reporting on health benchmarks such as HealthBench Professional and MedXpertQA rather than only coding/math
-
A subset questioned whether all numbers and comparisons were being interpreted correctly, especially around active params and external-model comparisons
- The most visible skepticism concerned the apparent Mythos FLOP “leak”. @iScienceLuvr suggested it was probably just an estimate, not a leak; @scaling01 later argued the original 6.1e27 FLOP figure was unrealistic and supplied a lower alternative estimate before posting a correction in @scaling01
-
There was also implicit skepticism in the field about whether zero synth / zero distillation is the right long-term recipe for best agentic performance, as noted by readers emphasizing synth-data deltas elsewhere, e.g. @stochasticchasm
-
Build’s announcements matter because they suggest Microsoft is no longer content with being only:
- Azure/OpenAI’s cloud host
- GitHub’s developer surface
- Copilot’s application shell It is also trying to be a first-party frontier model developer with its own model family, silicon stack, and post-training platform - The clean lineage / no distillation emphasis is strategically significant. It addresses enterprise concerns around IP provenance, future controllability, and dependence on external labs - The local AI emphasis matters because Microsoft is tying AI strategy to Windows and device distribution, not just to Azure. Build messaging repeatedly pushed the idea that reasoning models, planners, and agents can increasingly run on-device, not only in the cloud: @TheTuringPost, @yusuf_i_mehdi - The 109-page report matters because frontier-model transparency has generally been shrinking, especially around data, infra, and training methodology. Multiple researchers explicitly noted the disclosure level is uncommon at this scale: @eliebakouch, @nrehiew_ - The Build recap also showed Microsoft trying to integrate all layers of the stack:
- models: MAI family
- chips: MAIA 200
- cloud: Azure + Foundry
- OS: Windows agent runtime
- developer UX: Copilot app / VS Code / CLI
- retrieval/grounding: Web IQ
- hardware form factors: Solara / Scout concepts
-
This combination is why several observers described the event less as a normal dev conference and more as a coordinated move toward an agent platform spanning cloud, edge, OS, and custom models, e.g. @satyanadella, @mustafasuleyman, and @TheTuringPost
-
During/after Build, some users claimed a Microsoft slide inadvertently revealed training compute for Anthropic’s rumored Claude Mythos, with @swyx asking if Mustafa had leaked the FLOP count
- @scaling01 estimated the slide implied 6.1e27 FLOPs with a confidence interval based on pixel measurement, while @kimmonismus noted that would be around Gemini 3.1 Pro-scale compute
- That interpretation was subsequently challenged by @iScienceLuvr, who argued it was probably an estimate, and then by @scaling01, who posted a lower-range model-based estimate of 3.37e26 to 1.46e27 FLOPs and later said the original numbers were bogus in @scaling01
- The episode is useful mostly as context: Build’s compute/scaling messaging was detailed enough that people started trying to infer competitor training budgets from presentation materials
Developer tools, agents, and coding workflows
- OpenAI launched Sites in Codex, letting teams turn ideas/docs/plans into deployed internal websites/apps with auth and dynamic data, first for business/enterprise users, in @OpenAI, @TheRohanVarma, and @gdb
- OpenAI also expanded role-specific Codex plugins across sales, data analytics, creative production, product design, and public equity workflows, with access to 62 apps and 110 skills, from @OpenAI and @OpenAIDevs
- GitHub’s Copilot app and Microsoft’s Build push around agent-native software development were central to the day’s tooling news: @pierceboggan, @lukehoban, @GHchangelog
- Anthropic shipped a CLI for Claude Platform and upgraded Claude Code’s
/forkto run a background agent with exact context + prompt cache, in @ClaudeDevs and @ClaudeDevs - Nous launched Hermes Desktop, a local/native desktop surface for Hermes agents, in @NousResearch, @Teknium, and later Tailscale/Ollama integration notes from @Teknium and @ollama
- Cognition launched Devin Desktop, positioned as an agent-neutral desktop for managing local/cloud agents and handoff between local planning and cloud execution, in @cognition, @ScottWu46, and @russelljkaplan
Models, local inference, and routing
- H Company launched Holo 3.1, a local computer-use model family based on Qwen-style architecture, with checkpoints from 0.8B to 35B and formats including NVFP4, FP8, and Q4 GGUF; a popular summary cited 79.3% on AndroidWorld for the 35B model in @TeksEdge, with launch tweet from @hcompany_ai
- Perplexity announced hybrid agentic inference for Perplexity Computer, splitting work between local models on-device and frontier cloud models for privacy and token efficiency, in @perplexity_ai and @AravSrinivas
- OpenRouter data shared by @ttunguz showed open-weight models at 69.1% of token volume, versus 30.9% for closed models
- Commentary around model routing as a key future abstraction came from @ClementDelangue, @garrytan, @matanSF, and the counterpoint from @glennko, who argued enterprise production reliability makes generic routing harder than enthusiasts suggest
- Local-AI UX improvements also appeared in Hugging Face’s hardware compatibility checks and oMLX’s native macOS app release from @m_newhaus and @jundotkim
Research and evals
- Google DeepMind announced Co-Scientist, a Gemini-based multi-agent hypothesis generation system for science, claiming collaborations that helped identify liver fibrosis targets, ALS approaches, and genetic leads for aging, in @GoogleDeepMind, @GoogleDeepMind, and @GoogleDeepMind
- The new Crafter / CraftEditor work on editable scientific figure generation drew attention as a five-agent workflow for producing and refining figures plus raster-to-SVG conversion, in @HuggingPapers, @_akhaliq, and @TheTuringPost
- Tilde Research introduced Wall Attention, a RoPE-free attention method with diagonal forget gates, claiming training at 4k and generalization to 200k+ tokens plus Triton kernels and strong decode throughput, in @tilderesearch
- A robotics vision encoder claiming +22.5% real-world OOD success by encoding dynamics-awareness rather than relying on static-image pretraining was posted by @jbhuang0604
-
New evals/benchmarks of note:
-
PaintBench for precise image editing, where best model reached only 17.1%, from @itskaixu
- VSTAT for video state tracking, arguing frontier MLLMs remain weak at tracking evolving world state, from @PinzhiHuang and @sainingxie
- Data Agent Benchmark for enterprise data workflows, from @sh_reya
Inference, infrastructure, and agent systems
- Harvey + LangChain shared work on cheap verifiers for legal agents, showing DeepSeek V4 Flash could preserve 94–96% agreement with Opus 4.7 while reducing cost 18x in per-criterion mode and ~1000x in batch mode; for 3,200 RL rollouts, verification cost dropped from $18,000 to $18, in @harvey, @hwchase17, and @nikogrupen
- W&B relaunched Weave as agent-first observability with integrations across common harnesses and automated detection of failure modes, in @wandb and @neutralino1
- Prime-RL integrated Mooncake Store with vLLM for cross-node prefix / KV cache reuse, pitched as key for agentic rollouts, in @m_sirovatka
- Together detailed serving optimizations for MiniMax-M3, citing 81–125% throughput improvements via KV-block-major sparse attention, paged decode, optimized index scoring, and multimodal preprocessing, in @togethercompute
- MiniMax itself highlighted 1M context, native multimodality, desktop-computer operation, and MSA reducing attention’s share of decode time from ~30% to ~5%, in @MiniMax_AI
Ecosystem, hardware, and industrial capacity
- Westmag emerged from stealth to build American robot actuators and drone motors, with $11M raised led by a16z and participation from Founders Fund, Lux, NFDG, Menlo and others, in @boxcardavid, @packyM, and @oyhsu
- PyTorch noted NVIDIA adoption of OpenMDW-1.1, a permissive AI-model licensing framework, across four open-model families in @PyTorch
- Martin Scorsese publicly demonstrated narrow, preproduction use of FLUX for storyboarding with Black Forest Labs, framed as exploratory and complementary to hand-drawn work rather than generative replacement, in @robrombach and @TheRundownAI