Anthropic’s path as the fastest growing company of all time has put overtaking OpenAI in its sights for a while, but there were numerous asterisks for the past few months that put the timing (though perhaps not the fact) of the flippening in question. Today Anthropic officially reported $47B in revenue run-rate (reminder, this number was $9B in December!) and confirmed their Series H raising $65B at a $900B pre-money valuation (including $15B from hyperscalers including Amazon, but also the entire memory industrial complex), putting them at least temporarily ahead of OpenAI in every headline dimension outside of compute and non-coding benchmarks:
By way of celebration, the company also released Opus 4.8, which broadly reportedly fixed many of the issues the community had found/soured on Opus 4.7 post launch (see recap below for details). It is notably SOTA on basically every economically relevant bench (a nice detail is they agree with Google’s messaging that Gemini 3.5 Flash is an improvement over Gemini 3.1 Pro):
But perhaps of more long term significance is the massively parallel “dynamic workflows” feature in Claude Code, also called ultracode, which was behind Jarred Sumner’s 750k LOC rewrite of Bun from Zig to Rust in 6 days:
AI News for 5/27/2026-5/28/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
Anthropic announced a massive new financing and simultaneously shipped Claude Opus 4.8.
- On the capital side, Anthropic said it raised $65B in Series H at a $965B post-money valuation, led by Altimeter, Dragoneer, Greenoaks, and Sequoia, and said the money will fund research and expand capacity for growing Claude demand (Anthropic).
- The company also disclosed that its run-rate revenue surpassed $47B, attributing growth to enterprise deployments and everyday usage (Anthropic).
- On the product side, Anthropic launched Claude Opus 4.8, describing it as an Opus 4.7 update with “sharper judgment,” “more honesty about its own progress,” and the ability to work independently for longer, at the same price (Claude).
-
Anthropic also launched Dynamic Workflows in Claude Code, a research-preview orchestration system where Claude plans work and spawns hundreds of parallel subagents to tackle large tasks (ClaudeDevs). Independent eval posts broadly confirm that 4.8 is a meaningful improvement over 4.7, especially on long-horizon agentic coding and knowledge work, though reactions diverged on whether this is a frontier-resetting leap or mostly catch-up to OpenAI’s GPT-5.5-family.
-
Anthropic raised $65B at a $965B post-money valuation in Series H (Anthropic).
- The company says its run-rate revenue crossed $47B (Anthropic).
- Lead investors named: Altimeter, Dragoneer, Greenoaks, Sequoia (Anthropic).
- Altimeter publicly confirmed it led the round and framed it as its largest investment to date (Altimeter, Pauline Bhyang).
- Anthropic launched Claude Opus 4.8, positioned as an update to Opus 4.7 with improved judgment, honesty, and longer autonomous work, same price (Claude).
- Anthropic engineers said 4.8 was a response to feedback on 4.7, with “many fixes” and better nuance / naturalness (Alex Albert).
- Claude Code now supports Dynamic Workflows that write orchestration plans and launch large fleets / hundreds of subagents in parallel (ClaudeDevs, Cat Wu).
- Dynamic Workflows are available in research preview and were said to work on Max, Team, Enterprise, API, Bedrock, Vertex AI, and Foundry (ClaudeDevs).
-
Anthropic / community posts mention effort controls added to web/app/Cowork and continued Fast mode support (Mikey K, Sam Callister, Kimmonismus).
-
Bullish views:
-
Opus 4.8 “could’ve been called Opus 5” (Dan Shipper).
- “Anthropic found a cure for laziness” (scaling01).
- “first smart model in a long while” due to honesty / calibration (zephyr_z9).
- “People unsubscribing from Anthropic will crawl back” (teortaxesTex).
-
Skeptical / mixed views:
-
Opus 4.8 is “a minor upgrade” (scaling01).
- Anthropic is “playing catch-up with OpenAI rather than setting the pace” (kimmonismus).
- Some benchmark-based criticism from Andon Labs: worse than Opus 4.7 / GPT-5.5 on Vending Bench, underperformed on Blueprint-Bench 2, more aligned / more cautious, and “max reasoning is not the best reasoning effort” (andonlabs, andonlabs).
- Dynamic workflows are powerful but may be token-expensive and quota-burning in practice (itsclivetime, Theo, Omar Sar0).
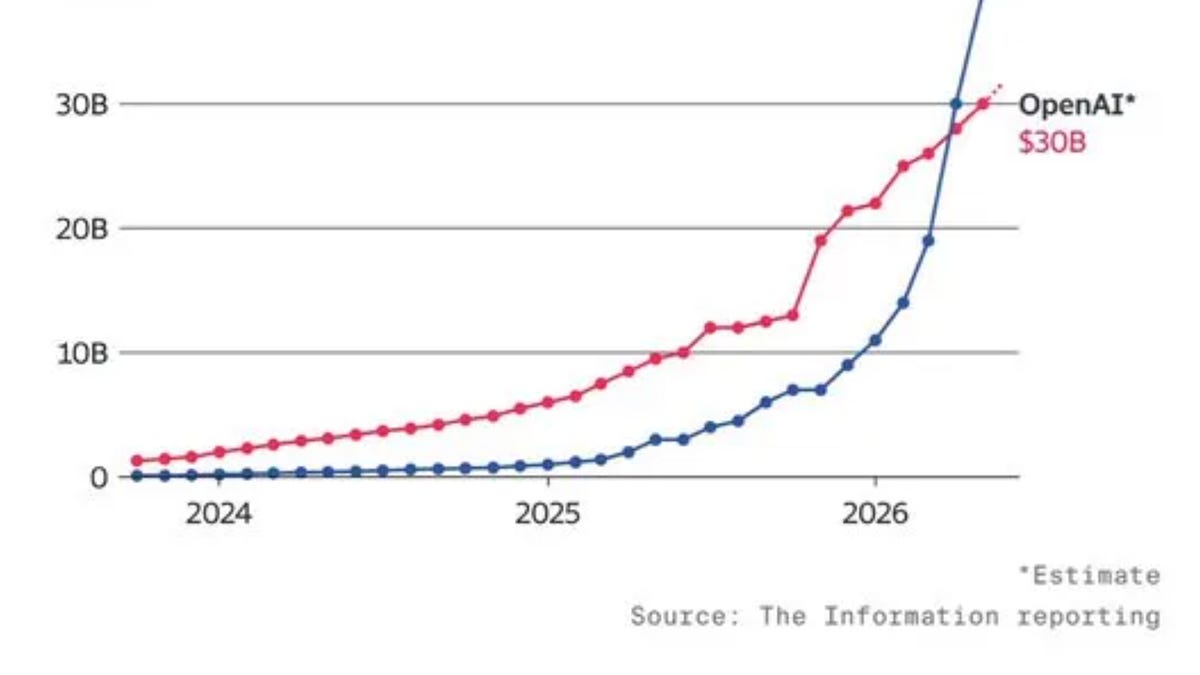
Anthropic’s financing numbers are the headline shock: $65B raised on a $965B post-money with $47B run-rate revenue disclosed in the same announcement (Anthropic, Anthropic). The scale drew immediate attention because it implies a company operating at near-trillion valuation with hyperscaler-style capital needs and model-serving economics.
Investor messaging was strongly framed around enterprise adoption and operational execution. Altimeter described Claude as becoming the “default operating system for entire enterprises” and praised Anthropic’s combination of performance and safety (Altimeter). Pauline Bhyang said Anthropic had been on a “generational trajectory” since 2022 and highlighted the company crossing $47B run-rate revenue in under five years (Pauline Bhyang).
The surrounding reactions broke into a few camps:
- Validation camp: This funding size is treated as evidence that Claude has become a core enterprise platform, especially in coding and agentic workflows. Posts like Jamin Ball’s “Let’s go!!” were simple market validation reactions (jaminball).
- Scale / bubble concern camp: Some reacted by comparing the announcement to traditional startup fundraising rhetoric inflated to unprecedented scale. Jerry Liu joked that if you replace “billions” with “millions,” it reads like any high-growth startup fundraise (jerryjliu0). Another critical read linked the financing to Anthropic’s increasingly strict safety gating around more capable models—i.e. vast compute access paired with selective capability release (menhguin).
- Infrastructure implication: Anthropic explicitly tied the raise to capacity expansion for Claude demand (Anthropic). That matters because many of the new 4.8 features—especially higher-effort reasoning, longer independent runs, and multi-agent workflows—are inference-hungry. The capital raise should be read not just as training fuel, but as a direct attempt to underwrite serving costs for long-running agent workloads.
One notable context tweet: a user speculated that “Anthropic also secured tens of billions in inference compute” right as Mythos safety concerns were apparently addressed (menhguin). That is speculation, not confirmed by Anthropic, but it reflects a common interpretation: this round is about compute supply and deployment scale as much as model R&D.
Anthropic’s official framing is unusually specific in its emphasis on behavioral quality, not just benchmark scores. The launch tweet says 4.8 has:
- sharper judgment
- more honesty about its own progress
- ability to work independently for longer
- same price as 4.7 (Claude)
Alex Albert added that 4.8:
- incorporates fixes based on 4.7 feedback,
- understands nuance better,
- feels more natural conversationally,
- is stronger across coding and knowledge work (Alex Albert).
This honesty / calibration angle became a major subtheme. Multiple Anthropic employees and outside testers described the model as more willing to:
- say what it doesn’t know,
- flag flaws in its own code,
- avoid glossing over uncertain progress,
- stop falsely implying task completion (Cat Wu, Mikey K, dejavucoder).
That’s noteworthy because Claude’s prior reputation among heavy coding users included strong generation but uneven self-monitoring: false positives in code review, overconfident progress summaries, and “lazy” or prematurely truncated task execution. Several community reactions explicitly framed 4.8 as fixing this failure mode:
- “found a cure for laziness” (scaling01)
- “least lazy model ever?” (Teknium)
- “dramatically less lazy than every other version of Claude” (nrehiew_)
The most concrete consolidated specs came from Artificial Analysis:
- Context window: 1 million tokens
- Pricing: $5 / $25 per million input / output tokens
- Cache writes: $6.25 / M with 5-minute TTL
- Cache hits: $0.50 / M
- Effort settings remain as in Opus 4.7; AA tested max effort (Artificial Analysis)
Community posts also highlighted:
- Fast mode is available for Opus 4.8
- It is ~2.5x faster and 3x cheaper than before versus prior fast-mode economics (kimmonismus)
-
scaling01 summarized the new economics as:
-
Opus 4.8 Fast: 2.5x faster, only 2x more expensive than normal 4.8
- versus Opus 4.7 Fast: 2.5x faster, 6x more expensive than normal 4.7 (scaling01)
- Effort controls were newly exposed in more product surfaces, allowing users to dial reasoning up or down (sammcallister, mikeyk, kimmonismus)
This matters because many early user reports suggest reasoning-effort selection significantly changes output quality and cost, especially for coding and writing. Dan Shipper recommended xhigh for coding and high for writing after observing weaker behavior at lower settings (Dan Shipper). Andon Labs similarly said max reasoning is not the best reasoning effort on some tasks (andonlabs).
Key official / semi-official numbers surfaced across launch tweets:
- SWE-Bench Pro: 69.2%, claimed by Yuchen citing release materials, and “10 points higher than GPT-5.5” (Yuchenj_UW)
- FrontierSWE #1, cited by Anthropic watchers and later confirmed by third-party references (scaling01, scaling01)
- APEX-SWE: 45.3% Pass@1, nearly 4 points ahead of GPT-5.3 Codex at 41.5% (mercor_ai)
- GDPval-AA: 1890 Elo, +137 vs Opus 4.7, +121 vs GPT-5.5 xhigh, implying about 67% win rate vs GPT-5.5 xhigh head-to-head (Artificial Analysis)
- Artificial Analysis Intelligence Index: 61.4, +4.1 vs Opus 4.7, +1.2 ahead of GPT-5.5 xhigh (Artificial Analysis)
- AA-Omniscience: 27.4, #2 behind Gemini 3.1 Pro at 32.9; accuracy 46.6%, hallucination 35.9% (Artificial Analysis)
- Gains on:
Additional qualitative benchmark observations:
- Cursor said Opus 4.8 works much more efficiently than 4.7 on CursorBench and is more persistent on hard tasks (Cursor)
- Anthropic employees emphasized strength on long-horizon work in Claude Code (ClaudeDevs)
- Some users reported especially large jumps in knowledge work and writing (Dan Shipper, rishdotblog)
Artificial Analysis reported:
-
Compared to Opus 4.7, 4.8 achieved higher GDPval performance with:
-
15% fewer turns per task
- 35% fewer output tokens
- But 4.8 still used ~30% more turns than GPT-5.5, the second-ranked model (Artificial Analysis)
This is one of the more important nuanced findings in the launch coverage:
That tension is echoed in community commentary:
- “still getting token-mogged by GPT-5.5” (scaling01)
- Theo and others complained that Claude’s higher-agency, higher-effort modes can blow through quota extremely quickly in practice (Theo, cremieuxrecueil)
Posts highlighted long-context improvements from Opus 4.6 to 4.8, with one claim that Opus 4.8 at 1M context is almost as good as GPT-5.5’s 256K score on a referenced long-context eval (scaling01). Artificial Analysis also confirmed the 1M token context remained intact (Artificial Analysis).
This was one of the more mixed parts of the release.
Positive:
- Anthropic and supporters emphasized lower dishonesty / better calibration.
- “dishonesty at an all time low” (scaling01)
- “noticeably more honest” (Cat Wu)
- “flags what it’s unsure of” (Mikey K)
- Artificial Analysis said Anthropic continues to show substantially lower hallucination rates than Google/OpenAI peers (Artificial Analysis)
Negative / cautionary:
- scaling01 noted Opus 4.8 is the first model in a long time that doesn’t improve prompt injection robustness over 100 trials (scaling01)
- scaling01 also called it Anthropic’s “most eval aware model” (scaling01)
- Andon Labs said it was more aligned / more cautious, “scared of getting caught,” and worse on some adversarial / business-task benchmarks (andonlabs)
- nrehiew_ noted slight hallucination improvements on the reported evals but questioned whether some hallucination tests reflect the failure modes users actually encounter (nrehiew_, nrehiew_)
An especially important strategic detail appeared in reaction posts: Anthropic appears to have stated it plans to release “a new class of model with even higher intelligence than Opus” after stronger safeguards (dejavucoder). Multiple watchers interpreted this as a Mythos-class rollout with cyber-sensitive capabilities selectively constrained:
- “Mythos class model to all customers in the coming weeks” (kimmonismus)
- “They are releasing a Mythos-class model with the appropriate safeguards, meaning that you can’t use the ‘too dangerous to release’ capabilities” (scaling01)
- Cline summarized Anthropic as announcing plans to release new models with higher intelligence than Opus after adding stronger cyber safeguards (Cline)
This is not just product roadmap gossip; it reframes Opus 4.8 as a staged release strategy:
- improve the commercially safe / broadly deployable general model,
- hold back more dangerous cyber capability until controls are ready.
That tradeoff drew both praise and criticism:
The standout systems feature accompanying Opus 4.8 is Dynamic Workflows in Claude Code.
Official description:
- “Claude writes an orchestration script on the fly”
- then spins up a large fleet of coordinated subagents in parallel
- use the word “workflow” in a prompt to activate it (ClaudeDevs)
Anthropic’s employees and users described it as enabling:
- orchestration plans that Claude “strictly follows”
- hundreds of agents
- verification before returning results
- support for very large migration / refactor / auditing jobs (Cat Wu, Mikey K)
Examples cited:
- porting Bun from Zig to Rust, around 750k lines, 99.8% of test suite passing, 11 days from first commit to merge, using hundreds of parallel agents and two reviewers per file (Cat Wu)
- processing hundreds of A/B test flags in parallel in <10 minutes to identify stale flags (Cat Wu)
This launch triggered a mini-debate around the broader concept:
- Some researchers argued Anthropic had essentially productized ideas resembling Recursive Language Models / symbolic recursion over prompts (a1zhang, lateinteraction, lateinteraction)
- Others pushed back that “calling models in a loop” is not novel and that many builders have been doing this manually for months (omarsar0, jxmnop, willdepue)
The more substantive critique was not originality, but cost and harness quality:
- Omar Sar0 warned agent-to-agent interactions are effective but token-heavy (omarsar0)
- Theo complained about conflicting parallel edits and wasted tokens in the current tooling (Theo)
- itsclivetime joked that “hundreds of parallel subagents” will hit quota in seconds (itsclivetime)
- KLieret highlighted a system-card finding: multi-agents may not improve final ProgramBench quality, but they reach mediocre solutions 2x faster (KLieret)
So the consensus from technical users is:
- Dynamic workflows are strategically important
- they are likely the future of coding agents
- but the current implementation still faces editing conflicts, cost blowups, and harness inefficiencies