We normally focus on technical stories, but occasional large fundraisings are noteworthy in themselves, and the Cerebras IPO (after one pulled S-1 and a fantastic 750MW partnership and $10-$20B stake/deal with OpenAI) this week, certainly qualifies as a growing theme supporting the Inference Inflection, just 6 months after the shock execuhire of Groq by NVIDIA for $20B. CBRS 0.00%↑ ended today at $280, a market cap of $60 billion, which is tremendous validation for Big Chip and their believers.
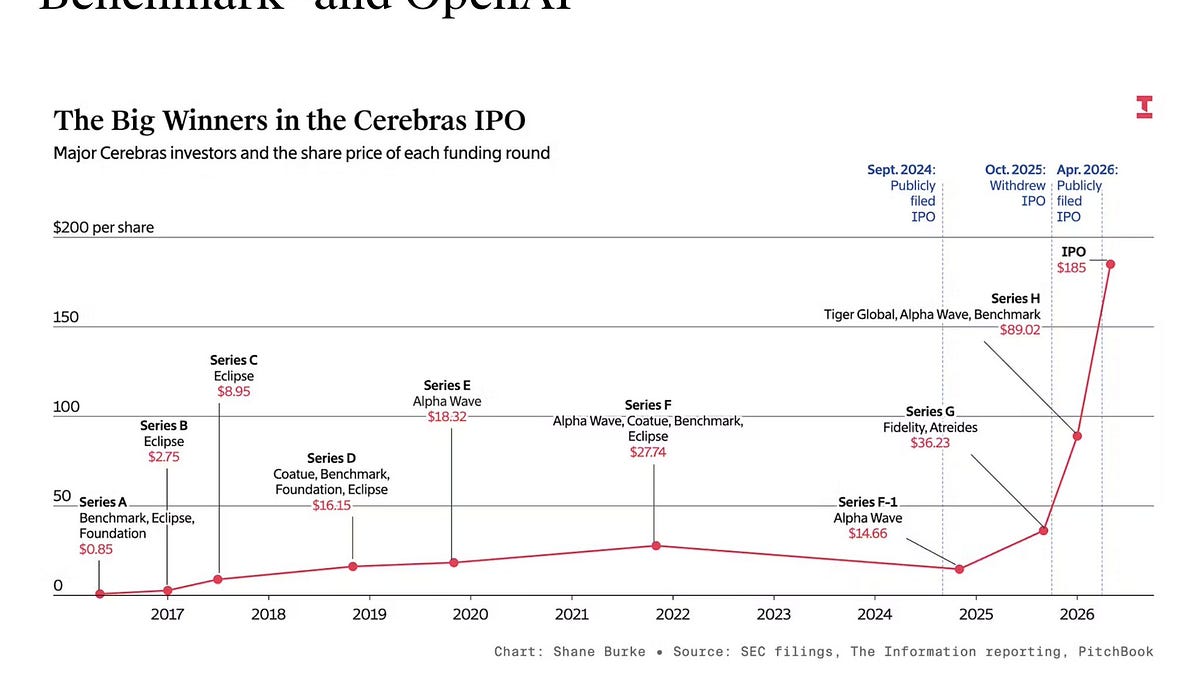
This image from Amir Efrati summarizes the Decade of Cerebras:
Cerebras’ financials are now fully public, but the focus of discussions center around the supply:
[Andrew Benson@AndrewBenson
Cerebras - what you really need to know - this IPO is going to fly regardless given Groq with no real customers sold for $20 billion to Nvidia and Cerebras is already in deployment with OpenAI - but they have problems on lack of access to wafers and TSMC until at least 2028 -
6:09 PM · May 5, 2026 · 19.9K Views
8 Replies · 5 Reposts · 110 Likes](https://x.com/andrewbenson/status/2051726066839130593?s=12)
More details below, and the Head Research Scientist of Cerebras speaks at AIE Singapore later today on the livestream:
AI News for 5/14/2026-5/15/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
Cerebras returned to the timeline as an IPO story, with investors and adjacent infra voices framing the company as a long-running contrarian hardware bet that finally looks vindicated. The most directly relevant tweet is from investor Ishan N. Taneja, who said he “didn’t believe” early Cerebras claims, then concluded the skeptic he doubted “was totally right,” praising Cerebras for persistence, execution, and for having “built a banger chip,” while noting this was Hanabi’s first IPO @ishanit5. A second Cerebras-specific datapoint came from CNBC’s Deirdre Bosa quoting Cerebras CFO Bob Komin pushing back on the “small models only” narrative: Komin said Cerebras serves models of all sizes, that there is “no limit” to the size of models it can serve, and that Cerebras is currently serving trillion-parameter models, including internal OpenAI models, specifically naming “OpenAI 5.4 and 5.5” @dee_bosa. A nearby contextual tweet from Apoorv Vyas explicitly linked “the Cerebras IPO” to a Stanford discussion on compute scarcity, inference demand, routing, and open source, suggesting the IPO was being interpreted not as a generic capital-markets event but as part of the inference infrastructure cycle @apoorv03.
- Cerebras is being discussed in the context of an IPO @ishanit5, @apoorv03.
-
Cerebras CFO Bob Komin said:
-
Cerebras serves all model sizes.
- There is “no limit” to model size it can serve.
- Cerebras is serving trillion-parameter models.
-
It is serving internal OpenAI models, specifically OpenAI 5.4 and 5.5 @dee_bosa.
-
Cerebras “did controversial things for the right reasons,” “the team slaps,” and “they built a banger chip” are investor judgments, not independently verified facts @ishanit5.
- The implication that the IPO is a validation of Cerebras’s long-term strategy is an interpretation emerging from the investor tone and surrounding infra discourse, not a formal claim from the company in these tweets.
- The CFO’s claim that there is “no limit” to model size is partly factual framing and partly marketing language; engineers should read it as “the company believes its serving architecture scales to current frontier workloads,” not literally unbounded compute.
The tweet corpus is light on historical specs, but it does contain several notable operational claims relevant to Cerebras’s technical positioning:
- Trillion-parameter model serving: Cerebras CFO says the company is currently serving trillion-parameter models @dee_bosa.
- Named customers/workloads: Komin specifically says these include internal OpenAI 5.4 and 5.5 @dee_bosa.
- Strategic wedge: The framing is clearly inference/serving, not just training. Apoorv ties the IPO discussion to “compute scarcity,” “rising inference demand,” and “model routing” @apoorv03.
Those tweets align with Cerebras’s broader known positioning in the market: wafer-scale hardware, extreme on-chip memory bandwidth, and system architectures optimized to reduce the bottlenecks that appear when serving large models with low latency. Even though those specific chip specs are not in the tweet set, the CFO’s “trillion-parameter” comment is technically meaningful because it implies the company wants to be understood as a serious serving platform for frontier-scale models, not a niche accelerator for mid-sized open models.
Cerebras has spent years in the “ambitious but contentious” bucket in AI hardware. The investor comment captures the core narrative arc well: the company took a path that many found implausible or commercially dubious, but did so with persistence and enough execution to stay alive through multiple compute cycles @ishanit5.
The subtext of that praise is important for hardware engineers:
- Cerebras has long represented a non-NVIDIA architectural thesis.
- Its strategy has been to attack the scaling problem with a different physical and system design philosophy, rather than merely competing on conventional accelerator economics.
- That made it inherently controversial, because the market often discounts bespoke architectures unless they win a very specific workload.
The IPO recap chatter suggests the company’s story has shifted from “can this architecture survive?” to “is this exactly the kind of differentiated serving stack the market now needs?”
That shift is happening because the AI infra market has also shifted:
- From pure training prestige toward inference economics.
- From benchmark snapshots toward serving giant models in production.
- From GPU abundance assumptions toward compute scarcity and routing discipline @apoorv03.
In that environment, a company that can credibly say it serves trillion-parameter internal frontier models gets a very different hearing than it would have a few years ago @dee_bosa.
- The most bullish take is from investor Ishan N. Taneja: skepticism gave way to admiration, with emphasis on persistence, execution, and a successful contrarian chip bet @ishanit5.
- Bob Komin’s quote is also strategically bullish: it reframes Cerebras as a platform for frontier-scale inference, not a side player @dee_bosa.
-
Apoorv’s comment places Cerebras in the center of a live systems question—compute scarcity amid rising inference demand—which is where a differentiated serving architecture could matter most @apoorv03.
-
A neutral read is that Cerebras’s IPO matters less as a public-markets event than as a signal that investors believe there is room for non-GPU-default infra companies in the frontier stack.
- Another neutral takeaway: even if Cerebras has genuine technical differentiation, the important question is not “is the chip elegant?” but “can it sustain utilization, software compatibility, and commercial adoption in a market increasingly organized around incumbent ecosystems?”
No tweet in the supplied set directly attacks the Cerebras IPO. But there are implicit reasons an expert audience would remain cautious:
- “No limit to model size” is standard executive rhetoric; in practice, limits show up in memory hierarchy, batch/latency tradeoffs, interconnect behavior, software ergonomics, and workload mix.
- Serving internal OpenAI workloads is a strong claim, but without details on share of traffic, latency tier, cost/token, utilization, or exact deployment role, it is hard to know whether this reflects broad strategic reliance or narrower targeted usage.
- The history of AI hardware is full of technically impressive architectures that failed commercially because software, developer adoption, or ecosystem gravity overwhelmed raw hardware merit.
The Cerebras IPO story lands at a moment when AI infra is being repriced around a few hard truths visible elsewhere in the tweet set:
- Inference is becoming the dominant compute market. Pearl, Together, and others are explicitly talking about inference economics and token costs @prlnet, @simran_s_arora.
- Serving giant models is now a product requirement, not just a lab flex. Multiple tweets discuss trillion-scale models, large-model cadence, and rapid RL/post-training-driven improvements @scaling01, @kimmonismus.
- Capital intensity is under scrutiny. Kimmonismus notes hyperscaler capex crossing $600B and a large gap between AI infra spending and AI revenue, warning that the market is watching infra economics closely @kimmonismus.
In that context, Cerebras matters if—and only if—it can make a durable case that a nonstandard architecture can improve the economics or latency profile of frontier inference enough to justify ecosystem switching costs.
Officially, the strongest claim in the tweet set is from CFO Bob Komin: Cerebras already serves trillion-parameter OpenAI internal models @dee_bosa.
What is missing from the tweet set is independent benchmark-style validation:
- no cost-per-token comparison,
- no latency percentile data,
- no throughput numbers,
- no context-length specifics,
- no software compatibility details,
- no utilization figures.
So the right technical posture is:
The IPO recap, then, is less “Cerebras won” and more “Cerebras stayed alive long enough for the market to become more favorable to its thesis.”
Codex, GitHub Copilot App, and the New Coding-Agent Surface Area
- OpenAI’s Codex mobile/app rollout dominated product chatter. Users described building websites from a bar, controlling Macs from iPhone, and treating laptops as “satellite devices” while an always-on Mac mini runs sessions in the background @flavioAd, @nickbaumann_, @PaulSolt, @rileybrown.
- Codex is rapidly becoming a multi-surface agent platform: tweets this cycle point to a meaningful broadening of where and how coding agents run: mobile-first workflows via Codex Mobile walkthroughs, iPad/VPS session management from @npew, Telegram/home-server remote setups from @itsclivetime, and hints of “locked use” for Mac control while the machine is locked from @kimmonismus. OpenAI’s dev team also shared adoption figures via @etnshow: 4M+ weekly active users, 5x more messages per user, and 1M+ app downloads in the first week.
- The surrounding ecosystem is moving quickly to plug into Codex rather than compete only at the app layer: Ollama added Codex app support with local/open-model launch paths and cloud model recommendations; Zed now supports ChatGPT subscription access in its agent, preserving the same subscription/rate-limit model as Codex; and third-party extensions are appearing, including MagicPath as a native canvas inside Codex and a portable
/goalcommand extracted into MCP/slash-command form by @secemp9. Community momentum was visible in meetup reports from London, Portugal, and Paris planning. - GitHub is making a parallel bet on the coding harness, not just the model: the VS Code/Copilot team emphasized that the user experience is shaped by the coding harness—context assembly, tool use, execution loops, memory—more than by the base model alone in their behind-the-scenes post shared by @code and @pierceboggan. Product features highlighted this week include agent merge from @davidfowl, and terminal risk assessment badges with AI explanations for commands from @code. The broader trend is clear: the competitive frontier is shifting from “best model” toward best harness + UX + integrations.
Agent Harnesses, Search, Evaluation, and Reliability Engineering
- Search for coding agents is being rethought around primitives, not embeddings: the strongest thread here is the “grep/search over vector DBs” argument. @omarsar0 highlighted a paper showing grep-style text search, wrapped in the right agent harness, can match or beat embedding-based retrieval on coding-agent tasks; @dair_ai echoed the takeaway. Relatedly, @lintool joked that the “two-parameter model” for agentic search is BM25, and maybe the zero-parameter version is grep. This aligns with Cloudflare-adjacent experimentation too: @YoniBraslaver compared SDK vs MCP on monday.com’s GraphQL API, finding 1 step / 15k tokens for SDK versus 4 steps / 158k tokens for a real MCP server—8.4x token cost for the same output.
- Agent evals and observability are becoming first-class infra problems: several posts converged on the same theme that evals for autonomous systems are harder, not easier, as agents get longer-horizon and more tool-rich. @palashshah called out the difficulty of modern eval design; @cwolferesearch compiled a broad benchmark map spanning Terminal-Bench, Tau-Bench, GAIA, WorkArena, OSWorld, MLE-Bench, PaperBench, GDPval, and others. New benchmark proposals included FutureSim, which replays real-world events temporally to test continual updating and forecasting in native harnesses like Codex/Claude Code, and follow-up commentary from @nikhilchandak29 arguing that test-time compute scales gracefully in forecasting too.
- Reliability concerns are shifting from hallucinations to system-level failure modes: @random_walker argued that black-box “genie” interfaces increase the verification burden because users can’t see reasoning traces, tool use, memory, or intermediate state. @mitchellh made the sharper infra analogy: companies may be drifting into an “MTTR is all you need” mindset for AI-generated software, creating resilient catastrophe machines where local metrics look fine while global system comprehensibility decays. On the tooling side, LangChain pushed the other direction with Interrupt announcements covering LangSmith Engine, SmithDB, managed Deep Agents, sandboxes, gateway, and context hub, while @ankush_gola11 emphasized sub-second median write latency for trace ingestion as a practical requirement for agent observability.
Training, Optimization, and Inference Efficiency
- Optimizer work is broadening beyond the Adam family again: @zacharynado summarized the zeitgeist succinctly: the “sloptimizer” field is just getting started with Shampoo and Muon-gen style methods after the graveyard of Adam variants. Two concrete updates landed: SODA, a wrapper that adds no hyperparameters, removes weight-decay tuning, and improves a base optimizer, with the notable claim that SODA[Muon] beats Muon even when Muon gets a tuned weight-decay sweep; and general continued interest in Muon/Shampoo from replies and references.
- Fast/slow learning and pedagogical supervision were notable training ideas this cycle: @agarwl_ described “Learning, Fast and Slow”, combining slow learning in weights via RL with fast learning in context/prompt (“fast weights”) optimized with GEPA, claiming better data efficiency, adaptability, and less forgetting than RL alone. On the supervision side, Pedagogical RL and Late Interaction’s explainer argue for learning not merely from correct outputs but from correct, teachable rollout distributions, while @bradenjhancock summarized related work on teacher models that are penalized for taking leaps students can’t follow.
- Inference optimization remains highly active at both systems and model levels: @ariG23498 recommended a deep dive on continuous batching, specifically the need to understand CUDA streams, events, synchronization, and CPU/GPU decoupling to avoid idle GPUs in dynamic batching regimes. Meta researchers proposed Self-Pruned KV attention, where the model learns which keys/values to keep in persistent cache to reduce KV cache size and improve decoding speed. On the local inference side, @danielhanchen reported that Qwen small-model MTP GGUFs now run 1.8x faster, up from 1.4x two days prior, thanks to new llama.cpp speculative-decoding parameters.
Open Models, Serving Stacks, and the Agent Toolchain
- Open/local agent stacks are tightening around Hermes, Ollama, and portable runtimes: ClawRouter integrating Hermes Agent, Teknium’s claims of surpassing OpenClaw in token volume, and Grok support in Hermes Agent via SuperGrok subscriptions all point to continued consolidation around interoperable agent shells. NVIDIA published a practical deployment path to run Hermes Agent locally on DGX Spark via Ollama. @onusoz also highlighted a major usability gap: one-click local model deployment for end users still doesn’t really exist, despite increasing demand.
- Serving infrastructure around open multimodal and scientific models continues to mature: vLLM highlighted Baseten’s production deployment of vLLM-Omni for multi-stage audio, streaming multimodal, and real-time TTS workloads often dominated by closed APIs. They also shipped day-0 support for Intern-S2-Preview, described as an open-source scientific multimodal foundation model with an early capability in material crystal structure generation. Additional tooling updates included Hugging Face’s call for agentic kernel development in the kernels project, and Capa, which turns OpenAPI specs into Cloudflare service bindings with 5,852 generated methods across platforms like Stripe, GitHub, Slack, Twilio, and Kubernetes.
- Document/search infra also saw concrete product work: Weaviate v1.37 added per-property accent folding, per-property stopword presets, and a /v1/tokenize endpoint for debugging BM25 tokenization. Cohere pushed Compass as a stack for retrieval over difficult documents using visual parsing plus search embeddings. On the benchmarking side, ParseBench leaders Infinity-Parser2-Pro (35B) and Flash (2B) were credited with 5M+ synthetic parsing samples and a joint RL algorithm across document/element/chart parsing tasks.
Anthropic, OpenAI, xAI, and Competitive Dynamics
- The strongest competitive signal was around developer-product pressure, not just benchmark pressure: @Yuchenj_UW framed Anthropic’s recent moves as “running the Codex playbook” after getting xAI GPU capacity, and the most visible user-facing change was Anthropic resetting everyone’s 5-hour and weekly Claude rate limits, amplified by @kimmonismus as a likely response to competition and/or increased compute availability. Separate reports from @kimmonismus cited FT numbers putting Anthropic valuation at $900B and ARR at $45B by end of May, up sharply from earlier checkpoints.
- On model perception, several tweets point to widening domain specialization and frontier gaps: Epoch AI’s domain-specific ECI suggests Claude has a software-engineering advantage relative to its own general capability index, but under-indexes in math. At the same time, multiple posters were impressed by Claude/Mythos-level capability jumps: @scaling01 called Mythos “insane,” while @teortaxesTex said Mythos appears meaningfully stronger than GPT-5.5 in at least some use. The speculative next step on the xAI side is larger scale still: @scaling01 expects a new 1.5T xAI model soon.
- OpenAI expanded the “ChatGPT as personal agent” thesis into finance: ChatGPT announced a personal finance experience for Pro users in the U.S., with secure financial-account connections, spending analysis, and grounded Q&A over user-authorized data. @fidjissimo tied it to the same pattern as health-record integrations: more structured personal context flowing into the agent. @kimmonismus argued this could compress parts of the fintech assistant layer, citing internal finance benchmarks where GPT-5.5 Thinking scored 79/100 and GPT-5.5 Pro 82.5/100 on complex personal-finance tasks.
Top tweets (by engagement)