하모닉이 Deep Agents와 LangSmith로 Scout를 재구축하고 유저 리테션을 4배 증대한 방법


스타트업을 찾거나 조사해야 한다면 Harmonic이 최고입니다. 벤처캐피탈 펀드를 위한 소싱 도구로 설립되었으며, 현재는 비공개 시장에서 일어나는 일을 추적하는 다양한 투자자를 지원합니다.
Scout는 하모닉의 AI입니다. 창업팀의 배경을 이해하는 것부터 틈새 기술의 자금 조달 트렌드를 분석하는 것까지, 사용자가 하모닉의 데이터에 대한 질문을 할 수 있는 대화형 인터페이스입니다. Scout를 Deep Agents와 LangSmith로 재구축하는 것은 제품 반복을 수개월에서 며칠로 단축했으며, 팀이 사용자를 위한 "투자 자문가"와 같은 새로운 가치를 발휘하고 새로운 시장으로 TAM을 확장할 수 있게 했습니다.
손으로 만든 파이프라인 유지의 비용
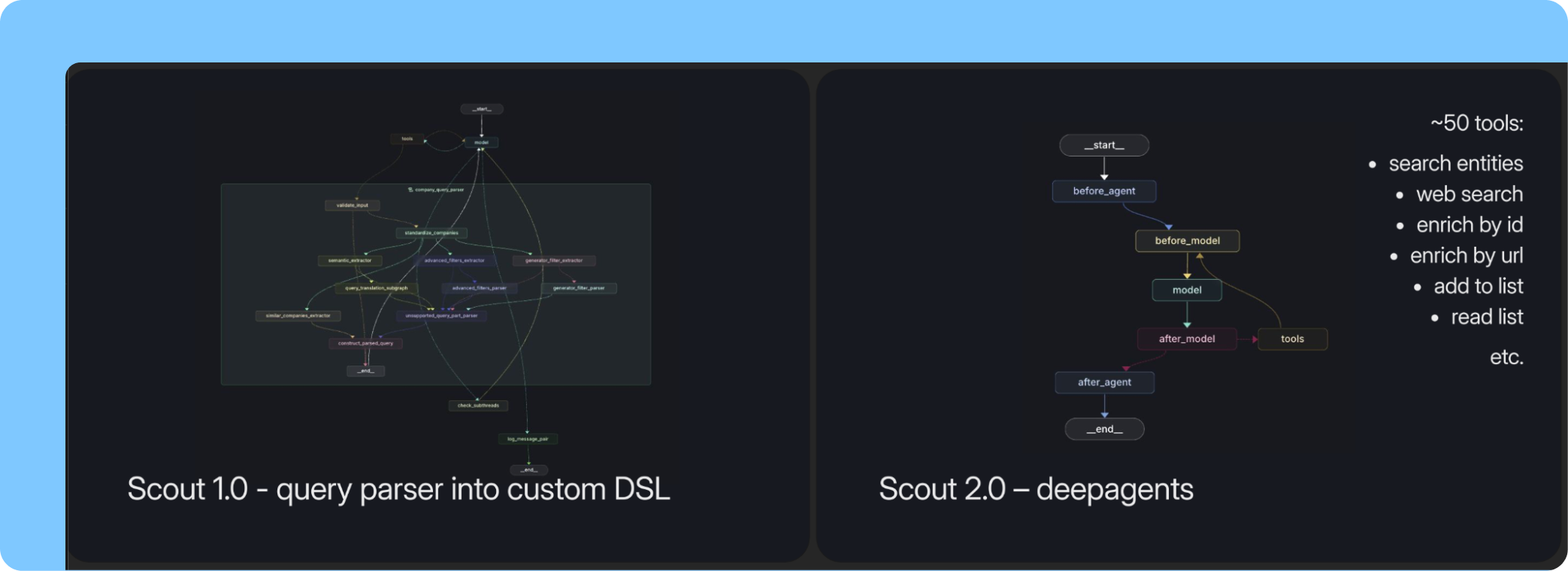
Scout의 첫 번째 버전은 사용자가 하모닉의 방대한 공개 및 비공개 데이터에 온보딩하고 상호작용하는 방식을 간소화했습니다. 모든 노드에서 LangSmith evals를 포함한 구성 가능한 부분 그래프로 구축된 Scout V1은 이미 강력한 LangGraph 기반 에이전트였습니다. 투자자는 자연어로 검색할 수 있으며, Scout는 복잡한 쿼리("상위 투자자로부터 지난 1년간 자금을 조달한 SF 또는 뉴욕의 AI 회사를 보여달라. 내 팀의 누군가와 연결된"와 같은)를 하모닉의 데이터 인덱스에 걸쳐 정확한 필터 구성으로 변환했습니다.
사용자는 더 이상 세부 필터 매개변수를 수동으로 구성하고 만들고 저장할 필요가 없었지만, 아키텍처가 경직되어 있었습니다. 워크플로우 밖의 모든 의도는 실패했으며, 유지하려면 수백 개의 evals가 필요했고, 각각의 새로운 기능은 새로운 부분 그래프를 의미했습니다.
사용자들이 개인화된 아웃리치 초안 작성이나 추상적인 투자 논제 검색 같은 것들을 요청하기 시작했을 때, Scout는 따라가지 못했습니다. 하모닉은 열린 범위의 작업을 처리할 수 있고 지속적인 재조정 없이 기본 모델이 진화함에 따라 개선될 수 있는 아키텍처가 필요했습니다.
새로운 에이전트 하네스: Deep Agents에서 Scout 재구축
Scout의 리드 엔지니어인 Austin Berke는 Scout V2를 그들의 이전 접근 방식의 거의 정반대로 설명합니다:
"전에는 경직된 구조를 구축하고, evals을 작성하고, 모든 노드를 지루하게 반복하는 데 많은 시간을 보냈습니다. 이번에는 이렇게 생각했습니다: 최고의 가장 스마트한 모델을 사용하고, 우리의 데이터와 상호작용하는 신중한 도구에 접근 권한을 주고, Deep Agents가 어떻게 하는지 봅시다. 그리고 즉시 놀라운 개선을 보았습니다."
새로운 아키텍처는 의도적으로 단순합니다. Deep Agents 하네스의 단일 최고 모델은 두 가지 도구 카테고리에 접근합니다. 하나는 하모닉의 글로벌 데이터 계층(4천만 개 회사, 2억 명, 23만 투자자)을 쿼리합니다. 다른 하나는 파이프라인 목록, CRM 노트, 이전 이메일 및 LinkedIn 연결을 포함한 기업별 컨텍스트에 접근합니다.
Deep Agents 하네스는 장기 작업 실행과 컨텍스트 창 관리를 기본으로 관리합니다. V1의 다중 그래프 파이프라인과 비교하면, 복잡성의 일부입니다.
"모델은 막다른 길에 빠지지 않을 만큼의 기관을 가지고 있습니다. 우리는 항상 그래프를 최대한 단순하게 유지하기 위해 자신을 확인합니다."라고 하모닉의 제품 관리자인 Seth Wieder가 강조했습니다.
팀은 이전에 80% 좋은 Scout 결과 비율을 목표로 하는 내부 OKR을 유지했습니다. 그 "Scoutcome" 메트릭은 더 이상 적극적으로 논의되지 않습니다. 일관된 품질이 이제 기본입니다.
UX: 검색 도구에서 신뢰할 수 있는 자문가로
Scout V1은 대부분의 데이터 도구가 작동하는 방식으로 작동했습니다. 사용자는 검색을 입력하고, 목록을 검토하고, 개선한 다음 반복했습니다. Scout V2는 검색 상자보다는 신뢰할 수 있는 자문가처럼 기능합니다. 투자 논제를 제시하고 이에 부합하는 5개 회사를 선택하도록 요청할 수 있습니다. "10분 후 이 창업가를 만날 예정인데 내가 알아야 할 모든 것을 알려 달라"고 말할 수 있으며, Scout는 당신의 CRM, 이전 이메일, LinkedIn 연결 및 회사의 공개 프로필에서 끌어와서 전체 기록 시스템에 걸쳐 종합합니다.
Scout V2는 주요 에이전트 UX 긴장을 해결했습니다. Austin이 말하듯이: "에이전트는 코드처럼 느껴지는 것들을 좋아합니다. 사용자는 코드처럼 느껴지는 것들을 싫어합니다." 최고 모델의 시각 요소에 대한 자연 출력은 구조화되고 기술적입니다(예: SVG, HTML, JSON). 하지만 사용자는 풍부하고 직관적인 요소가 있는 깔끔한 채팅 창을 기대합니다. 두 가지를 연결하려면 Scout가 생산하는 모든 아티팩트에 대해 어디에 있는지, 누가 볼 수 있는지, 모델이 사용자가 보는 것을 어떻게 알고 있는지 결정해야 합니다.
팀의 설계 규칙이 되었습니다: 사용자가 보는 모든 것을 모델이 발견할 수 있어야 합니다. 그렇지 않으면 에이전트는 사용자가 후속 질문을 하는 순간 실을 잃게 됩니다.
예를 들어, 시각화와 회사 검색을 봅시다.
시각화
테스트 초기에 사용자가 Scout에게 시각적 시장 지도를 요청했고, 팀은 요청을 거부할 것으로 예상했습니다. 대신 Scout는 프론트엔드가 직접 렌더링할 수 있는 능력이 없었던 SVG 코드를 반환했습니다. 팀은 이것이 실패 모드가 아니라 의도적인 기능으로 바뀌는 방법을 파악하기 위해 굴곡을 따라갔습니다.
시각화는 이제 Scout 대화에서 첫 번째 클래스 원시입니다. 모델은 메시지의 일부로 시각화를 인라인으로 작성하고, 프론트엔드는 제자리에 렌더링합니다. 모델과 사용자 모두 같은 대화에서 같은 아티팩트를 봅니다. 팀은 차트 기능, 타임라인 기능 또는 시장 지도 기능을 설계할 필요가 없었습니다. 패턴(회의 준비, 연구 보고서, 팀 구성 타임라인)은 에이전트와 UX가 하나의 진실의 원천을 공유하기 때문에 반복됩니다.
회사 검색
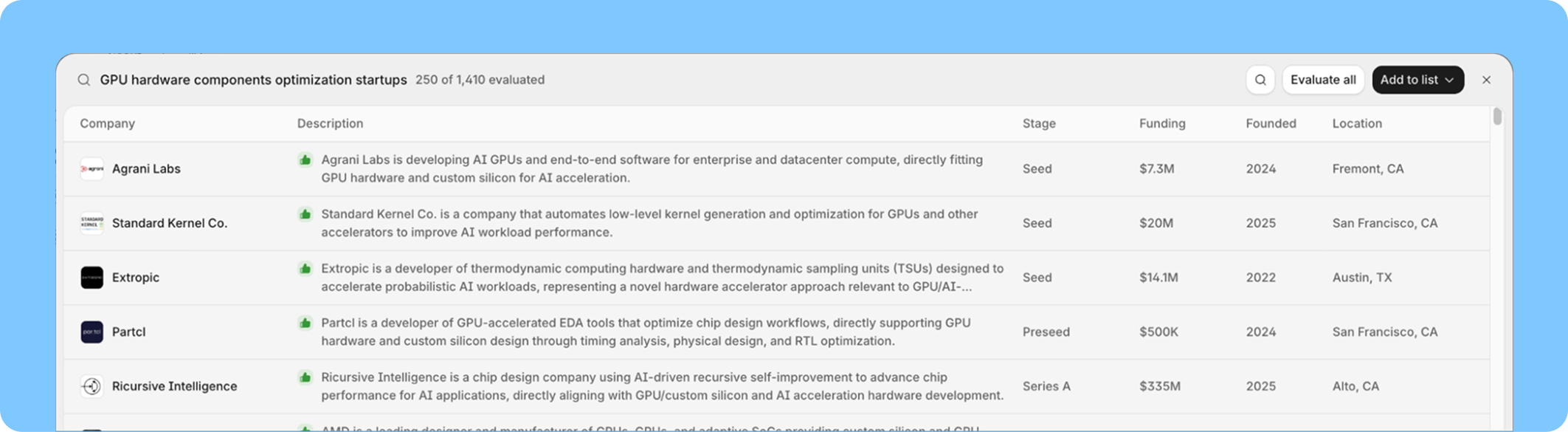
사용자는 Scout가 수천 개의 회사를 검색하길 원합니다. 채팅 메시지로 다시 스트리밍할 수 있는 것보다 훨씬 더 많습니다. Scout가 검색을 실행하고, 결과를 측면 패널에서 렌더링하고, 계속 진행하는 설계는 사용자가 "왜 그 3개가 맨 위에 있어?"라고 묻는 순간 무너집니다. 모델은 결과 세트를 본 적이 없으므로 답할 수 없습니다. Scout는 에이전트가 필요에 따라 읽을 수 있는 공유 파일 시스템에 결과를 기록함으로써 이를 해결하며, 모델이 사용자가 보는 것과 같은 데이터를 페이지할 수 있게 하는 도구와 함께합니다. 프론트엔드는 행이 도착할 때 렌더링합니다. 모델은 대화가 요청할 때마다 그 중 아무거나 다시 방문할 수 있습니다.
공유 파일 시스템 설계를 사용하면, Scout는 모든 사용 사례에 대한 사용자 정의 워크플로우를 구축할 필요가 없습니다. "모든 개별 사용 사례나 고객을 위한 고유한 워크플로우 경험을 구축할 필요가 없다는 것이 거대한 잠금 해제입니다."라고 Austin이 지적했습니다.
제품 개발 함의와 관련하여 Seth가 덧붙였습니다:
"Scout 이전에는 사용자가 우리 제품과 상호작용할 것으로 예상했던 방식으로 구축했습니다. 우리는 기능 요청을 받았고, 우선순위를 매기고, 트레이드오프를 했습니다. 지금 이 에이전트 모델에서는 사용자에게 원하는 방식으로 데이터와 상호작용할 수 있는 능력을 제공하고 어떻게 사용하는지 관찰합니다. 우리는 매일 창발적 사용 사례를 발견합니다."
LangSmith Deployment에서 프로덕션에서 Scout 실행
Scout 뒤의 팀은 리한하고 제품 중심입니다. LangSmith Deployment는 내구성 있는 스레드 실행, 사용 증가에 따라 무한정 확장할 수 있는 신뢰할 수 있는 배포, 관찰성을 위해 플랫폼 계층을 관리합니다. Austin은 이를 "설정 후 놔두기"로 설명하며, 팀은 하모닉의 제품을 구별하는 것(글로벌 회사 및 사람 데이터와 귀사의 컨텍스트 및 연결을 결합)에 대한 인터페이스 구축에 집중할 수 있게 해줍니다.
반복을 위해, 팀은 전체 대화 추적을 렌더링하는 내부 대시보드를 구축했으므로 엔지니어는 사용자가 본 것과 생성된 아티팩트를 정확히 볼 수 있습니다. 또한 그들은 자신의 AI 코딩 도구와 함께 LangSmith MCP를 사용합니다:
"LangSmith 추적을 끌어내서 실행 중인 코드와 어떻게 상호작용하는지 보고 무엇이 실제로 일어나고 있는지에 의해 정보를 얻은 변경을 할 수 있습니다. 느슨한 자체 개선 루프가 있습니다: 변경 작성, 그래프 실행, 추적 보기, 추적 다시 끌어오기."
LangSmith Engine의 초기 채택자인 팀은 Engine이 실패 모드를 식별하고 클러스터링하고 즉시 코드 개선과 evals을 제안하는 더 명시적인 자체 개선 루프의 이점도 얻습니다:
"우리의 Deep Agents 추적은 수십 또는 수백 개의 턴을 포함할 수 있어서 검토하고 패턴을 식별하는 것이 지루합니다. LangSmith Engine은 팀이 시간을 절약해줍니다. 단순히 새로운 실패 모드를 식별하는 것뿐만 아니라 proactively 제안하기도 합니다. evals과 이들을 신속하게 해결하기 위한 코드 변경,"이라고 Austin이 말했습니다.
Deep Agents로 전환하여 4배 리테션
사용자의 반응은 놀라웠습니다. 투자자들은 Scout를 "엄청나게 도움이 된다," "내 천국과 같다," "게임을 바꾼다"고 설명합니다. 더욱 더 말하는 것은 다른 회사들과 메모를 비교할 때 초기 단계 파트너가 관찰한 것입니다. "모두의 비결 무기가 Scout가 되고 있으며," 투자자는 동료와 논의할 필수 도구에 대해 이야기할 때 Scout가 산업 표준이 되고 있음을 인식합니다.
그 입소문 피드백은 사용 메트릭에 반영됩니다: Scout 사용자의 주 1~4주 리테션이 V1의 것보다 4배 올랐습니다. 그리고 Scout 사용자의 평균 세션 길이는 10배 증가했습니다. 사용자는 이제 일회성 회사 검색보다는 더 긴 다단계 대화를 수행합니다.
다음은 무엇인가: 더 큰 TAM
Scout가 제공하는 가치는 하모닉이 신흥 시장으로 확장할 수 있게 합니다. Scout는 고유한 스타트업 데이터베이스 덕분에 스타트업에 대한 모든 질문에 답할 수 있으며, 이는 투자 이상의 사용 사례를 잠금 해제합니다. Innovation and Corporate Development 팀, 재능 팀, 채용자, GTM 팀이 스타트업에 팔고 있는 것은 Scout를 사용하여 최신 정보를 유지하고 있습니다. 하모닉 팀은 스타트업에 기회를 제공하는 자신의 사명에 대해 그 어느 때보다 흥분합니다.
자신의 소유 데이터 계층에서 프로덕션 에이전트를 구축하려고 하나요? Deep Agents에 대해 알아보거나 문서를 읽어보세요.







당신의 에이전트가 실제로 무엇을 하고 있는지 확인하세요
LangSmith는 에이전트 엔지니어링 플랫폼으로, 개발자가 모든 에이전트 결정을 디버그하고, 변경 사항을 평가하고, 한 번의 클릭으로 배포할 수 있도록 도와줍니다.
How Harmonic Rebuilt Scout on Deep Agents and 4x'd Retention with LangSmith
If you need to find or research startups, Harmonic is the place to go. Founded as a sourcing tool for venture capital firms, the platform now supports a diverse range of investors tracking what’s happening in private markets.
Scout is Harmonic’s AI. A conversational interface where users can query Harmonic’s data for questions from understanding the background of a founding team, to analyzing funding trends in a niche technology. Rebuilding Scout on Deep Agents and LangSmith accelerated product iteration from months to days, allowing the team to unlock new value akin to an "investment advisor” for users and expand their TAM to new markets.
The Cost of Maintaining A Hand-Built Pipeline
The first version of Scout simplified how users onboarded and interacted with Harmonic’s vast amounts of public and private data. Built on composable subgraphs with LangSmith evals at every node, Scout V1 was already a capable LangGraph-powered agent. Investors could search in natural language, and Scout would translate complex queries (for example, “show me AI companies in SF or NY that have raised funding in the last year from top investors and have a connection to someone on my team”) into precise filter configurations across Harmonic's data index.
Users no longer had to configure, create and save detailed filter parameters manually, but it was architecturally rigid. Any intent outside its workflows would fail, maintaining it required hundreds of evals, and each new capability meant a new subgraph.
When users started asking for things like personalized outreach drafts or abstract investment thesis searches, Scout couldn't keep up. Harmonic needed an architecture that could handle an open-ended range of tasks and improve as the underlying models evolved, without constant re-tuning.
A New Agent Harness: Rebuilding Scout on Deep Agents
Austin Berke, lead engineer on Scout, describes Scout V2 as the near-opposite of their previous approach:
"Before, we spent a lot of time building rigid structures, writing evals, and tediously iterating on every node. With this version, we said: let's use the best and smartest models, give it access to thoughtful tools that interface with our data, and see how Deep Agents does. And immediately we saw incredible improvements."
The new architecture is deliberately simple. A single frontier model in a Deep Agents harness with access to two categories of tools. One set queries Harmonic's global data layer (40M companies, 200M people, 230K investors). The other accesses firm-specific context including pipeline lists, CRM notes, prior email and LinkedIn connections.
The Deep Agents harness manages long-horizon task execution and context window management out of the box. Compared to the multi-graph pipeline from V1, it's a fraction of the complexity.
"The model has the agency it needs to not run into dead ends. We're always checking ourselves to keep the graph as simple as possible," emphasized Seth Wieder, Product Manager at Harmonic.
The team previously maintained an internal OKR targeting an 80% good Scout outcome rate. That “Scoutcome” metric is no longer actively discussed; consistent quality is now the default.
UX: From Search Tool to Trusted Advisor
Scout V1 worked the way most data tools work. Users typed a search, reviewed a list, refined, and repeated. Scout V2 functions less like a search box and more like a trusted advisor. You can hand it an investment thesis and ask it to pick five companies aligned with it. You can say "I'm meeting with this founder in 10 minutes; tell me everything I should know," and Scout will pull from your CRM, prior emails, LinkedIn connections, and the company's public profile, then synthesize across your entire system of record.
Scout V2 resolved a key agent UX tension. As Austin puts it: "Agents love things that feel like code. Users hate things that feel like code." A frontier model's natural output for visual artifacts is structured and technical (e.g. SVG, HTML, JSON). Yet users expect a clean chat window with rich, intuitive elements. Bridging the two means deciding, for every artifact Scout produces, where it lives, who can see it, and how the model stays aware of what the user is looking at.
The team's design rule became: anything the user sees, the model must be able to discover. Otherwise the agent loses the thread the moment the user asks a follow-up question.
Take, for example, visualization and company search.
Visualizations
Early on in testing, a user asked Scout for a visual market map, and the team expected it to reject the request. Instead, Scout returned SVG code that the frontend didn't have the ability to directly render. The team leaned in to figure out how to turn this into an intentional feature rather than a failure mode.
Visualizations are now a first-class primitive in a Scout conversation. The model authors the visualization inline as part of its message, and the frontend renders it in place. Both the model and the user see the same artifact in the same conversation. The team didn't have to design a chart feature, a timeline feature, or a market map feature. The pattern (meeting prep, research reports, team-build-out timelines) repeats because the agent and UX share one source of truth.
Company search
Users want Scout to search across thousands of companies at a time—far more than can stream back as a chat message. The design where Scout fired a search, rendered results in a side panel, and moved on, breaks down the moment the user asks "why are those three at the top?" The model never saw the result set, so it can't answer. Scout solves this by writing results to a shared filesystem the agent can read from on-demand, paired with tools that let the model page through the same data the user is seeing. The frontend renders rows as they arrive. The model can revisit any of them when the conversation calls for it.
Using the shared filesystem design, Scout doesn't need a custom workflow for every use case. "Not having to build a unique workflow experience for every individual use case or customers is a huge unlock," noted Austin.
When it comes to the product development implications, Seth added:
"Before Scout, we'd build for how we expected users to interact with our product. We would get feature requests, prioritize them, and make tradeoffs. Now, in this agentic model, we give users the ability to interact with the data how they want to and we observe how they use it. We discover emergent use cases every day."
Running Scout in Production on LangSmith Deployment
The team behind Scout is lean and product-focused. LangSmith Deployment manages the platform layer for durable thread execution, reliable deployments that can scale infinitely as usage increases, and observability. Austin describes it as "set and forget," freeing the team to focus on building the interface for what makes Harmonic's product distinct (global company and person data combined with your firm’s context and connections) versus the infrastructure underneath.
For iteration, the team built an internal dashboard that renders full conversation traces so engineers see exactly what users saw, including any generated artifacts. They also use the LangSmith MCP alongside their AI coding tools:
"We can pull down LangSmith traces, see how they interact with the code being executed, and make changes informed by what's actually happening. There's a loose self-improving loop: make changes, execute a graph, see the trace, pull the trace back in."
As early adopters of LangSmith Engine, the team also benefits from a more explicit self-improving loop as Engine identifies and clusters failure modes, and suggests code improvements and evals on the spot:
"Our Deep Agents traces can contain dozens or hundreds of turns, which makes reviewing and identifying patterns tedious. LangSmith Engine saves our team hours of digging by not only identifying emerging failure modes, but also proactively suggesting evals and code changes to resolve them quickly,” said Austin.
4x Retention By Switching to Deep Agents
The response from users has been extraordinary. Investors describe Scout as "incredibly helpful,” "like my heaven, and "game-changing." Even more telling is what one early-stage partner observed when comparing notes with other firms—that "everyone's secret weapon is becoming Scout," with investors recognizing Scout is becoming industry-standard when discussing must-have tools with peers.
That word-of-mouth feedback is reflected in usage metrics: week-one to week-four retention of Scout users jumped to 4x what it was on V1. And the average session duration of Scout users has increased 10x as users now conduct longer, multi-step conversations versus one-off company searches.
What's Next: A Bigger TAM
The value Scout now provides allows Harmonic to expand to emerging markets. Scout can answer any question about startups thanks to its unique startup database, which unlocks use cases beyond investing. Innovation and Corporate Development teams, talent teams, recruiters, and GTM teams selling to startups are using Scout to stay in the know. And the Harmonic team remains as excited as ever about its mission to deliver opportunities to startups.
Want to build production agents on your own proprietary data layer? Learn about Deep Agents or read the docs.
See what your agent is really doing
LangSmith, our agent engineering platform, helps developers debug every agent decision, eval changes, and deploy in one click.