-
Fable 5 vs. GPT-5.6 Sol: NP-난해 문제에서 /goal은 도움이 되는가
Fable 5 vs. GPT-5.6 Sol: NP-난해 문제에서 /goal은 도움이 되는가 | GeekNews
<ul> <li>미공개 광섬유망 최적화 문제를 30분씩 풀게 한 결과, <strong>Fable 5</strong>가 최고 점수와 가장 안정적인 성능을 보였지만 <code>/goal</code>은 일관된 향상을 만들지 못함</li> <li><code>/goal</code>은 단순히 더 오래 작업하게 하는 기능이 아니라 <…
-
Codex 사용량 한도 리셋 추적
Codex 사용량 한도 리셋 추적 | GeekNews
<ul> <li>@thsottiaux의 X 공지를 추적해 <strong>Codex 사용량 한도 리셋 시점</strong>을 기록하며, 마지막 리셋은 2일 전임</li> <li>현재까지 <strong>35회</strong>를 집계했고 평균 대기 간격은 8.9일, 최장 공백은 67.7일임</li> <li>장애·지연·한도 계산…
-
브라우저에서만 돌아가는 한국어 AI 글 판별기
브라우저에서만 돌아가는 한국어 AI 글 판별기 | GeekNews
<p>얼마전에 Hacker News를 뜨겁게 달궜던 주제가 있습니다.<br /> 고전 ML로 AI Slop Text를 판별하는 게 생각보다 효과가 좋다는 블로그 글이었어요.</p> <p>https://news.ycombinator.com/item?id=48936880<br /> https://blog.lyc8503.net…
-
Claude Code, Rust로 작성된 Bun 도입
Claude Code uses Bun written in Rust now
<p>Article URL: <a href="https://simonwillison.net/2026/Jul/19/claude-code-in-bun-in-rust/">https://simonwillison.net/2026/Jul/19/claude-code-in-bun-in-rust/</a></p> <p>Comments UR…
-

Qwen 토큰 요금제
Qwen (@Alibaba_Qwen) on X
<p><a href="https://www.qwencloud.com/pricing/token-plan" rel="nofollow">https://www.qwencloud.com/pricing/token-plan</a></p> <hr /> <p>Comments URL: <a href="https://news.ycombina…
-
0.144 버전으로 새로고침된 번들 모델 메타데이터 백포트
Backport refreshed bundled model metadata to 0.144 by sayan-oai · Pull Request #33972 · openai/codex
<p>Article URL: <a href="https://github.com/openai/codex/pull/33972/files">https://github.com/openai/codex/pull/33972/files</a></p> <p>Comments URL: <a href="https://news.ycombinat…
-
AI 코드 검토가 타당한 반론이 될 수 없는 이유
AI 코드 검토가 타당한 반론이 될 수 없는 이유 | GeekNews
<ul> <li>LLM 코딩 도구의 잦은 오류를 사람이 모두 검토하면 된다는 해법은 <strong>코드 리뷰의 처리 한계</strong> 때문에 품질과 생산성을 함께 보장하기 어려움</li> <li>경험적 연구에 따르면 효과적인 리뷰는 한 번에 <strong>1시간·400 LOC</strong> 정도가 상한이며, 이를 넘…
-
Mamdani 뉴욕시장, 임대 광고에 AI 이미지를 몰래 사용할 수 없다고 밝혀
Mamdani 뉴욕시장, 임대 광고에 AI 이미지를 몰래 사용할 수 없다고 밝혀 | GeekNews
<ul> <li>뉴욕시는 부동산을 실제보다 매력적으로 보이게 만든 <strong>AI 생성·편집 이미지</strong>를 임대 광고에 사용할 경우 그 사실을 공개하도록 요구하는 방안을 추진함</li> <li>시 행정부의 <strong>Rental Ripoff Report</strong>는 이미지뿐 아니라 AI나 디지털 도…
-
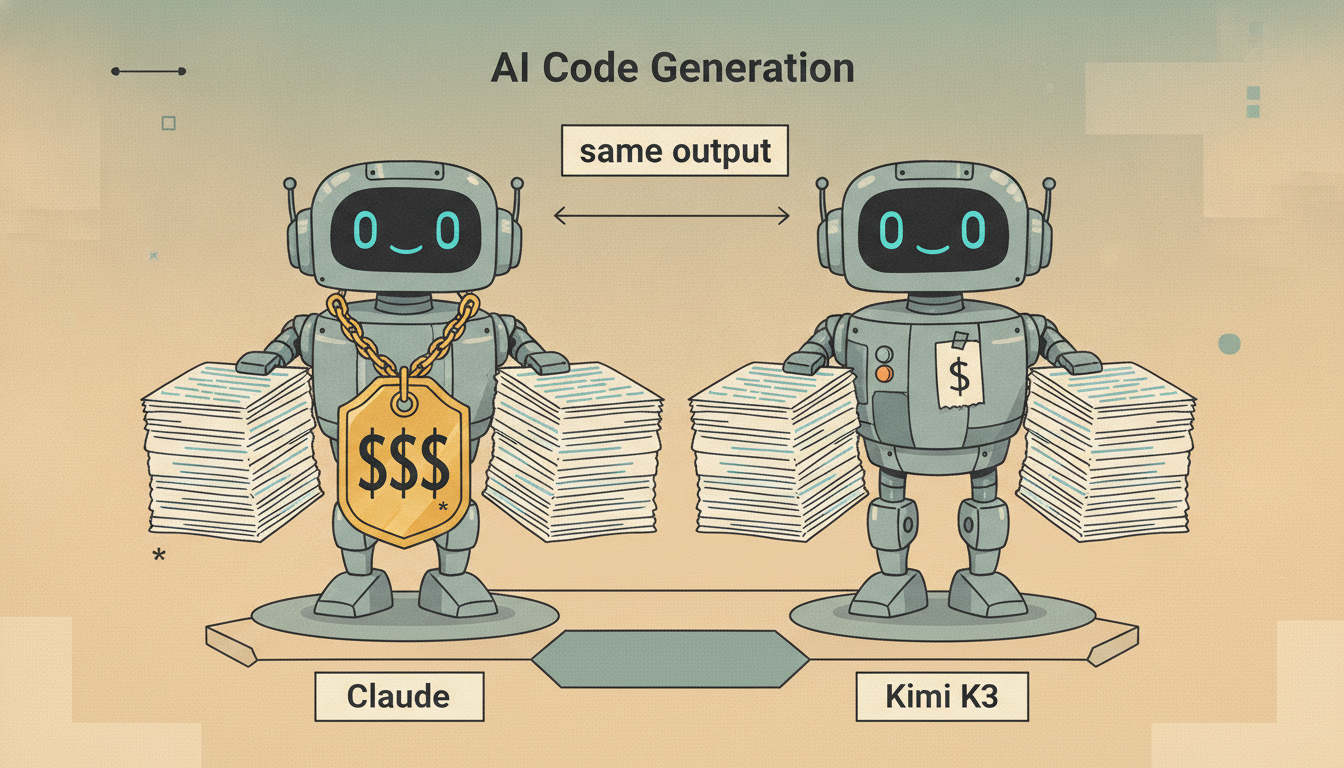
Kimi K3의 순간
Kimi K3의 순간 | GeekNews
<ul> <li>일상적인 코딩 작업에서 <strong>Kimi K3와 Claude</strong>를 병행한 결과, 출력 품질과 답변에 필요한 토큰 수에서 실질적인 차이를 구별하기 어려웠음</li> <li>Kimi K3 API는 100만 토큰당 입력 <strong>$3</strong>, 출력 $15로, 각각 $10와 $50…
-
안녕히, 그동안의 모든 Bikeshed에 감사드립니다
안녕히, 그동안의 모든 Bikeshed에 감사드립니다 | GeekNews
<ul> <li>FOSS의 미래를 바꿀 두 요인으로 <strong>LLM 기반 코드 리뷰</strong>와 <strong>연령 확인</strong>을 꼽으며, 특히 연령 확인이 현재 형태의 FOSS를 끝내는 계기가 될 것으로 내다봄</li> <li>LLM 코드 리뷰는 사람이 살피기 어려운 탐색 공간을 더 넓고 깊게 조사하…
-
GPT-5.6이 프롬프트로 볼록 최적화의 30년 공백을 메움
GPT-5.6이 프롬프트로 볼록 최적화의 30년 공백을 메움 | GeekNews
<ul> <li>제공된 본문은 GPT-5.6이나 볼록 최적화가 아니라, 모든 <strong>유한 단순군</strong>을 18개 무한 계열과 26개 산재군으로 분류하는 군론의 정리를 다룸</li> <li>유한 단순군은 소수처럼 유한군의 기본 구성 요소지만, 같은 <strong>합성열</strong>을 가진 비동형 군이 존…
-

OpenAI Codex 사용량 한도 리셋 추적
Codex Resets — OpenAI Codex Usage Limit Reset Tracker
<p>Article URL: <a href="https://codex-resets.com/">https://codex-resets.com/</a></p> <p>Comments URL: <a href="https://news.ycombinator.com/item?id=48963465">https://news.ycombina…
-
AI 기업 로고는 왜 항문처럼 보일까? (2025)
AI 기업 로고는 왜 항문처럼 보일까? (2025) | GeekNews
<ul> <li>AI 기업 로고에는 <strong>원형 윤곽과 중앙의 빈 공간</strong>, 방사형 요소, 부드러운 곡선, 그라데이션이 반복돼 의도치 않게 인체 구조를 연상시킴</li> <li>원은 완전함·무한함·친근함을 전달하고, 사람은 <strong>파레이돌리아</strong> 때문에 추상적인 형태에서도 익숙한 생…
-

Mamdani 시장, 임대 광고에 AI 이미지를 비밀리에 사용할 수 없다고 밝혀
Mayor Mamdani Says Landlords Can't Secretly Use AI Images to Advertise Properties
<p>Article URL: <a href="https://petapixel.com/2026/07/16/mayor-mamdani-says-landlords-cant-secretly-use-ai-images-to-advertise-properties/">https://petapixel.com/2026/07/16/mayor-…
-
Kimi K3의 순간
The Kimi K3 Moment
<p>Article URL: <a href="https://stephen.bochinski.dev/blog/2026/07/18/the-kimi-k3-moment/">https://stephen.bochinski.dev/blog/2026/07/18/the-kimi-k3-moment/</a></p> <p>Comments UR…
-
여유 Mac을 Claude Code가 완전히 제어하도록 설정하는 방법 - 단계별 가이드
How to set up your spare Mac for Claude Code to fully control - a step-by-step guide
<p>Article URL: <a href="https://ykdojo.github.io/claude-controls-mac/">https://ykdojo.github.io/claude-controls-mac/</a></p> <p>Comments URL: <a href="https://news.ycombinator.com…
-
유튜브 댓글에서 체스 플레이 매크 프로그램
유튜브 댓글에서 체스 플레이 매크 프로그램 | GeekNews
<p>유튜브 댓글을 이용해 구독자 집단 지성과<br /> 체스 AI(Stockfish)가 대결하는 자동 체스 봇을 만들어봤습니다.</p> <p>봇은 10분마다 고정댓글의 대댓글을 수집한 뒤, 최근 작성된 댓글 중 SAN(Standard Algebraic Notation) 체스 표기법으로 작성된 수만 추려 가장 많은 좋아요…
-
GPT-5.6이 프롬프트로 볼록 최적화의 30년 격차를 해소하다
GPT-5.6 used a prompt to close a 30-year gap in convex optimization
<p>Article URL: <a href="https://old.reddit.com/r/math/comments/1uxj3cy/after_openais_cdc_proof_announcement_gpt56_used_a/">https://old.reddit.com/r/math/comments/1uxj3cy/after_ope…
-
LLM에서 추론 노력 제어하기
Controlling Reasoning Effort in LLMs
How LLMs Learn Low-, Medium-, and High-Effort Reasoning Modes
-

스택오버플로우 - 스택 익스체인지 데이터 탐색기
Stackoverflow - Stack Exchange Data Explorer
<p>Article URL: <a href="https://data.stackexchange.com/stackoverflow/query/1953768#graph">https://data.stackexchange.com/stackoverflow/query/1953768#graph</a></p> <p>Comments URL:…
-

Fable 5 vs. GPT-5.6 Sol: NP-난제에서 /goal이 도움이 될까?
Fable 5 vs. GPT-5.6 Sol on an NP-Hard Problem: Does /goal Help? - Charles AZAM
<p>Article URL: <a href="https://charlesazam.com/blog/fable-5-gpt-5-6-sol-goal/">https://charlesazam.com/blog/fable-5-gpt-5-6-sol-goal/</a></p> <p>Comments URL: <a href="https://ne…
-
Claude Code의 잘못 설계된 자동 진행 기능 해부
Claude Code의 잘못 설계된 자동 진행 기능 해부 | GeekNews
<ul> <li>Claude Code <code>2.1.198</code>은 <code>AskUserQuestion</code>에 60초간 답이 없으면 모델이 자체 판단으로 작업을 계속하는 <strong>자동 진행 기능</strong>을 기본 활성화했지만, 출시 당시 변경 로그와 문서에는 기록하지 않았음</li> <li>…
-
Kimi K3와 펠리컨 벤치마크에서 여전히 배울 수 있는 것
Kimi K3와 펠리컨 벤치마크에서 여전히 배울 수 있는 것 | GeekNews
<ul> <li>Moonshot AI가 공개한 <strong>Kimi K3</strong>는 2.8조 개 매개변수를 갖춘 자사 최고 성능 모델로, 웹사이트와 API에서 제공되며 오픈 가중치는 2026년 7월 27일까지 공개될 예정임</li> <li>자체 벤치마크에서는 Claude Opus 4.8 max와 GPT-5.5 h…
-
루프 안의 인간은 지쳤다
루프 안의 인간은 지쳤다 | GeekNews
<ul> <li>LLM 프로그래밍은 생산성을 높이는 동시에 개발자가 의도와 품질을 계속 통제해야 하는 <strong>감독 피로</strong>를 키워, 만족감과 지속 가능성을 흔듦</li> <li>모델은 그럴듯한 코드를 빠르게 만들지만 복잡한 변경의 일관된 의도를 놓칠 수 있어, 인간이 늘어난 결과물을 검토하고 수정하는 …
-
Claude Fable 5, 7월 20일부터 Max/Team Premium 요금제에 기본
Claude Fable 5, 7월 20일부터 Max/Team Premium 요금제에 기본 | GeekNews
<ul> <li><strong>맥스/팀 프리미엄</strong> 사용자는 7월 20일부터 Fable 5를 요금제 사용 한도의 <strong>50%까지</strong> 이용 가능</li> <li><strong>프로/팀 스탠다드</strong>는 구독 기본 한도 대신 "Usage 크레딧"으로 계속 이용하며,…
-
Kaiser 간호사들 "AI 감시가 업무와 환자 돌봄을 악화"
Kaiser 간호사들 “AI 감시가 업무와 환자 돌봄을 악화” | GeekNews
<ul> <li>Kaiser Permanente 상담·트리아지 간호사들은 <strong>15분 이상 통화</strong>, 통화 간격, 지침 준수 여부를 추적하는 성과 관리가 전문적 판단과 환자 돌봄을 위축시킨다고 말함</li> <li>2024년 시험한 AI는 간호사의 <strong>공감과 목소리 톤</strong>까지 …
-
-
2026년 7월 오픈소스 AI 현황
2026년 7월 오픈소스 AI 현황 | GeekNews
<ul> <li>오픈 웨이트 모델은 코딩·지시 이행·일반 지식에서 폐쇄형과 비슷한 수준에 도달했고, 추론 비용도 36개월간 <strong>50배 하락</strong>하면서 경쟁의 중심이 모델 자체에서 <strong>에이전트 하네스</strong>로 이동함</li> <li>2026년 중반 OpenRouter에서 오픈 웨이트…
-
Apple, OpenAI 직원 수십 명에게 법적 서한 발송
Apple, OpenAI 직원 수십 명에게 법적 서한 발송 | GeekNews
<ul> <li>Apple이 자사 출신 OpenAI 직원 약 <strong>40명</strong>에게 문서와 통신 기록을 보존하고 Apple 변호사와 면담하라는 개별 법적 서한을 발송함</li> <li>OpenAI가 Apple의 <strong>기밀 하드웨어 설계</strong>를 도용했다는 소송을 뒷받침할 증거를 확보하기…
-

Kaiser 간호사들, AI와 직장 감시가 업무와 환자 돌봄을 악화시킨다고 주장
Kaiser nurses say AI, workplace surveillance are making their jobs and patient care worse - Local News Matters
<p>Article URL: <a href="https://localnewsmatters.org/2026/07/15/kaiser-nurses-say-ai-workplace-surveillance-are-making-their-jobs-and-patient-care-worse/">https://localnewsmatters…

