-
LLM 비판론자들이 옳다. 그래도 나는 LLM을 쓴다
LLM 비판론자들이 옳다. 그래도 나는 LLM을 쓴다 | GeekNews
<ul> <li>저작권·환경·윤리 문제와 저품질 산출물, 오픈소스 신뢰 붕괴, 주니어 육성 약화, 지정학적 종속을 인정하면서도 LLM을 <strong>사고의 품질을 높이는 도구</strong>로 계속 활용함</li> <li>LLM은 기존의 생각·의견·구조를 증폭하므로, 사람의 판단이 없으면 유창한 쓰레기를 대량 생산하지만…
-
OpenAI·Anthropic에서 일한 전 YC 창업자, 최소 105명
OpenAI·Anthropic에서 일한 전 YC 창업자, 최소 105명 | GeekNews
<ul> <li>스타트업 인수나 폐업 이후의 경로를 추적한 결과, YC 창업자 최소 105명이 <strong>OpenAI 또는 Anthropic</strong>에서 일한 것으로 집계됨</li> <li>과거 CEO·CTO였던 이들도 현재는 <strong>Member of Technical Staff</strong>가 가장 …
-
LM Studio Bionic: 오픈 모델을 위한 AI 에이전트
LM Studio Bionic: 오픈 모델을 위한 AI 에이전트 | GeekNews
<ul> <li><strong>LM Studio Bionic</strong>은 코딩·조사·문서 작업을 로컬 또는 클라우드의 오픈 모델로 처리해, 개인정보와 AI 사용 비용을 직접 통제할 수 있는 별도 앱임</li> <li>모델은 기기에서 직접 실행하거나 <strong>LM Link</strong>로 연결할 수 있으며, 복…
-
browser-rs-mcp - 초경량 멀티 에이전트 스텔스 브라우저 컨트롤러
browser-rs-mcp - 초경량 멀티 에이전트 스텔스 브라우저 컨트롤러 | GeekNews
<h2>1. Motivation?</h2> <p>에이전트 하나에 크롬 하나. 이게 기본값이면 에이전트당 RAM이 500MB~1GB씩 나갑니다. 에이전트 5개만 굴려도 브라우저만으로 RAM 2.5~5GB.</p> <p>거기다 Playwright는 CDP 세션 자체가 기본으로 하나에 ~180MB를 먹습니다. 브라우저 프로세스…
-
SpaceX 주가, IPO 공모가 아래로 내려가며 상승분 반납
SpaceX 주가, 장중 IPO 공모가 아래로 밀리며 상승분 모두 반납 | GeekNews
<ul> <li>상장 직후 50% 넘게 올랐던 SpaceX 주가는 처음으로 장중 <strong>공모가 135달러 아래</strong>로 내려가며 지난달 상승분을 모두 반납함</li> <li>이후 일부 회복해 <strong>135.27달러로 마감</strong>했지만, IPO 당시 시가총액 2조 2,000억 달러와 AI 사…
-

오픈 소스 AI의 현황 — V1.0 · 2026년 7월
The State of Open Source AI — V1.0 · July 2026
<p>Article URL: <a href="https://stateofopensource.ai/">https://stateofopensource.ai/</a></p> <p>Comments URL: <a href="https://news.ycombinator.com/item?id=48947825">https://news.…
-
100달러 AI 뮤직비디오 제작 대결: Claude Fable 5 vs. GPT-5.6 S
100달러 AI 뮤직비디오 제작 대결: Claude Fable 5 vs. GPT-5.6 S | GeekNews
<ul> <li>Claude Fable 5와 GPT-5.6 Sol에 같은 곡과 가사, <strong>25·100달러 예산</strong>, 웹 검색과 ffmpeg를 제공하고 조사부터 영상 생성·편집까지 맡긴 결과, 네 번 모두 원곡을 결합한 완전한 길이의 영상을 자율적으로 완성함</li> <li>생성 모델과 제작 방식도 …
-

Apple, OpenAI 직원 수십 명에게 법적 편지 발송
Apple targets dozens of OpenAI employees with legal letters
<p>Article URL: <a href="https://www.ft.com/content/1b8c9d52-88a9-426b-ba47-f1811f859166">https://www.ft.com/content/1b8c9d52-88a9-426b-ba47-f1811f859166</a></p> <p>Comments URL: <…
-

AI 시대를 위한 스코어카드
A scorecard for the AI age
Sarah Friar, CFO of OpenAI, introduces a practical AI scorecard to measure ROI through useful work, cost per successful task, dependability, and return on compute.
-
우리는 떼돈을 벌게 될 것이다
우리는 떼돈을 벌게 될 것이다 | GeekNews
<ul> <li>약 <strong>5년에 걸친 시나리오</strong>에서 AI 코딩 확산은 주니어 채용을 줄이고 코드 복잡성을 누적시켜, 이를 정리할 숙련된 시니어 개발자의 몸값을 크게 끌어올릴 수 있음</li> <li>코딩 모델이 주니어 개발자를 대체할 만큼 발전했다고 보는 기업은 인력 대신 더 많은 <strong>토…
-
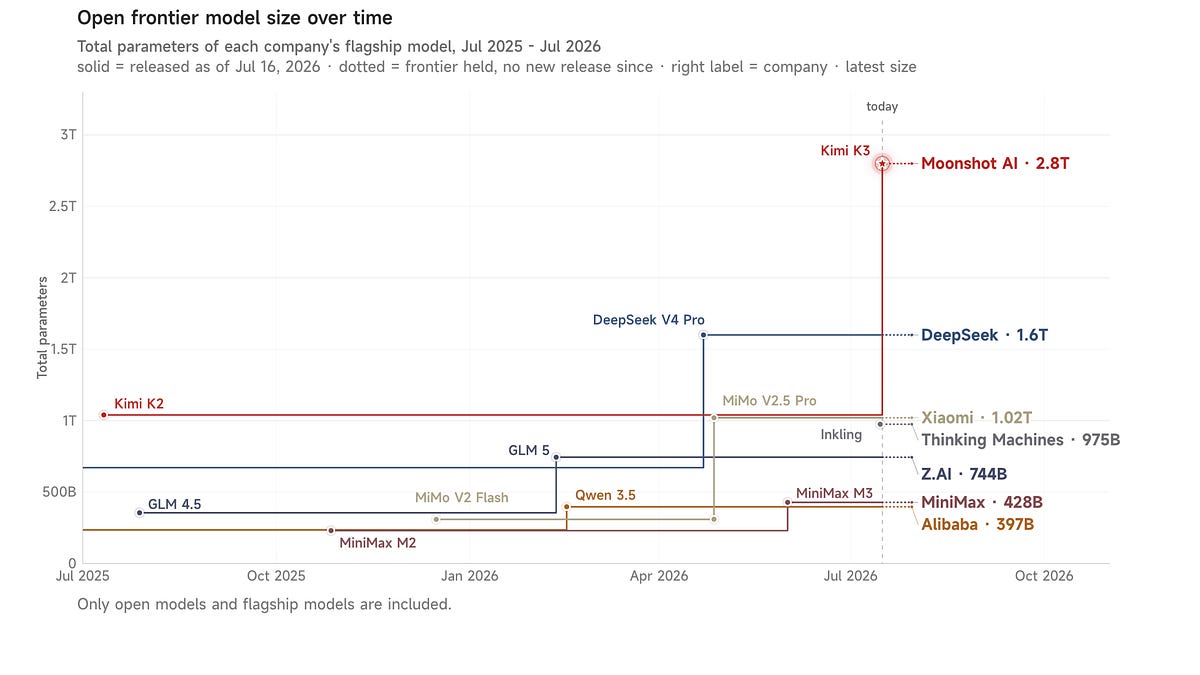
Kimi K3 2.8T-A50B: 지금까지 출시된 가장 큰 오픈 모델; Opus 4.8급 성능에 Sonnet 5 가격대
[AINews] Kimi K3 2.8T-A50B: the largest open model ever released; Opus 4.8-class at Sonnet 5 pricing
a great week for open models continues.
-
Pandas 창시자가 말하는 AI·Apache Arrow·소프트웨어 엔지니어링의 미래
Pandas 창시자가 말하는 AI·Apache Arrow·소프트웨어 엔지니어링의 미래 [유 | GeekNews
<ul> <li>Pandas와 Apache Arrow를 만든 경험을 바탕으로, AI 시대에도 고성능 데이터 시스템과 소프트웨어를 설계하는 <strong>전문성·판단력·취향</strong>이 핵심이라고 봄</li> <li>Apache Arrow는 표 형식 데이터를 위한 범용 <strong>인메모리 기반 계층</strong>…
-
커널 개발에서 LLM 사용에 관한 Linus Torvalds의 견해
커널 개발에서 LLM 사용에 관한 Linus Torvalds의 견해 | GeekNews
<ul> <li><strong>Linux 커널</strong>은 반AI 프로젝트가 아니며, AI는 다른 도구들과 마찬가지로 <strong>유용한 도구</strong>임</li> <li>LLM에 대한 반감이 있는 사람들이 존재하지만, 이 사안에 대해서는 <strong>최상위 메인테이너로서 단호한 입장</strong>을 취함…
-
NotebookLM, Gemini Notebook으로 이름 변경
NotebookLM, Gemini Notebook으로 이름 변경 | GeekNews
<ul> <li>Google은 <strong>독립형 연구 도구</strong>라는 제품 성격을 유지하면서 Gemini 앱과 Google Search 등 자사 생태계와의 연동을 확대하기 위해 NotebookLM을 <strong>Gemini Notebook</strong>으로 변경함</li> <li>2023년 Google I…
-
Kimi K3 공개 - 개방형 프론티어 인텔리전스
Kimi K3 공개 - 개방형 프론티어 인텔리전스 | GeekNews
<ul> <li>Kimi K3는 <strong>2.8조 파라미터</strong>, 네이티브 비전, 100만 토큰 컨텍스트를 갖추고 장시간 코딩/지식 작업/추론을 겨냥한 세계 최초의 공개 3T급 모델</li> <li><strong>Kimi Delta Attention/Attention Residuals</strong>와 8…
-

Kimi K3와 펠리칸 벤치마크로부터 배울 수 있는 것
Kimi K3, and what we can still learn from the pelican benchmark
<p>Chinese AI lab Moonshot AI <a href="https://www.kimi.com/blog/kimi-k3">announced Kimi K3</a> this morning, describing it as their "most capable model to date, with 2.8 trillion …
-

LM Studio Bionic 소개: 오픈 모델을 위한 AI 에이전트
Introducing LM Studio Bionic: the AI agent for open models
<p>Article URL: <a href="https://lmstudio.ai/blog/introducing-lm-studio-bionic">https://lmstudio.ai/blog/introducing-lm-studio-bionic</a></p> <p>Comments URL: <a href="https://news…
-
$100 AI 뮤직 비디오: Claude Fable 5 대 GPT-5.6 Sol
$100 AI Music Video: Claude Fable 5 vs. GPT-5.6 Sol
<p>Article URL: <a href="https://www.tryai.dev/blog/ai-music-video-arena-claude-vs-gpt-5.6">https://www.tryai.dev/blog/ai-music-video-arena-claude-vs-gpt-5.6</a></p> <p>Comments UR…
-
GPU 없이 13년 된 Xeon에서 Gemma 4 26B를 초당 5토큰으로 실행하기
GPU 없이 13년 된 Xeon에서 Gemma 4 26B를 초당 5토큰으로 실행하기 | GeekNews
<ul> <li>2013년형 듀얼 Xeon E5-2690 v2와 DDR3로 구성된 서버에서 <strong>Gemma 4 26B-A4B Q8_0</strong>을 CPU만으로 구동해 디코딩 약 5.2토큰/초, 프롬프트 평가 약 16토큰/초를 달성함</li> <li><code>ik_llama.cpp</code>의 고속 경로는…
-

NotebookLM이 이제 Gemini Notebook이다
NotebookLM is now Gemini Notebook
<p>Article URL: <a href="https://blog.google/innovation-and-ai/products/gemini-notebook/notebooklm-gemini-notebook/">https://blog.google/innovation-and-ai/products/gemini-notebook/…
-

청소년이 안전한 AI에 접근할 권리
Why teens deserve access to safe AI
Learn how OpenAI is making ChatGPT safer for teens with age-appropriate protections, learning tools, parental controls, and expert partnerships.
-
Kimi K3 기술 블로그: 오픈 프론티어 인텔리전스
Kimi K3 Tech Blog: Open Frontier Intelligence
<p><a href="https://www.kimi.com/en" rel="nofollow">https://www.kimi.com/en</a><p>Kimi K3 Intelligence, Performance & Price Analysis: <a href="https://artificialanalysis.ai/models/…
-

에이전틱 코딩 및 지식 작업을 위해 설계된 Kimi AI K3
Kimi AI with K3 | Built for Agentic Coding & Knowledge Work
<p>Article URL: <a href="https://www.kimi.com/en">https://www.kimi.com/en</a></p> <p>Comments URL: <a href="https://news.ycombinator.com/item?id=48935342">https://news.ycombinator.…
-

미래의 랩은 데이터 센터처럼 느껴져야 한다
🔬 The Lab of the Future Should Feel Like a Data Center — Andy Beam & Rafa Gómez-Bombarelli, Lila Sciences
Lila is betting that science, not the internet, is the last untapped source of training data. We went to find out what that actually looks like in a room full of robots.
-
내가 Google DeepMind를 떠난 이유
내가 Google DeepMind를 떠난 이유 | GeekNews
<ul> <li>Google DeepMind 연구 과학자였던 Alexander Matt Turner는 Google이 DHS·ICE에 클라우드 서비스를 제공하고, 미 국방부와 <strong>자율살상무기·대규모 AI 프로파일링을 구속력 있게 금지하지 않은 계약</strong>을 체결하자 양심상 남을 수 없다며 퇴사함</li>…
-

LLM 비평가들의 말이 맞다. 그래도 나는 LLM을 사용한다
The LLM Critics Are Right. I Use LLMs Anyway.
<p>Article URL: <a href="https://www.theocharis.dev/blog/llm-critics-are-right-i-use-llms-anyway/">https://www.theocharis.dev/blog/llm-critics-are-right-i-use-llms-anyway/</a></p> …
-

Codex가 OpenAI 창의팀의 협력자가 되다
How Codex became a collaborator for OpenAI’s creative team
How OpenAI’s creative team uses Codex to build custom creative tools, accelerate ideation, and prototype faster with context-aware AI.
-
Grok Build가 오픈 소스로 공개됨
Grok Build가 오픈 소스로 공개됨 | GeekNews
<ul> <li>SpaceXAI의 터미널 기반 AI 코딩 에이전트 <strong>Grok Build</strong>를 구성하는 Rust 소스와 에이전트 런타임이 공개됐으며, 저장소는 SpaceXAI 모노레포에서 주기적으로 동기화됨</li> <li>전체 화면 <strong>TUI</strong>에서 코드베이스 이해, 파일 …
-

Thinky의 Inkling: 975B-A41B 멀티모달, 새로운 최고 미국 Apache 2.0 오픈 모델
[AINews] Thinky's Inkling: 975B-A41B multimodal, new best American Apache 2.0 open model (with Inkling-Small, 276B-A12B)
Thinky's first full LLM release is a banger and bonus: it's open weights!
-
앤트로픽·블랙스톤, 15억 달러 규모 'AI 구현' 합작사 Ode 출범
앤트로픽·블랙스톤, 15억 달러 규모 'AI 구현' 합작사 Ode 출범 | GeekNews
<blockquote> <p>Anthropic, Blackstone, Hellman & Friedman 3사가 엔터프라이즈 AI 구현 전문 회사 "Ode with Anthropic"을 7월 15일 정식 공개함. 5월에 결성된 15억 달러 규모 조인트벤처로, 프런티어 모델과 전문 엔지니어를 묶어 기…