-
Ornith-1.0 - 에이전트형 코딩을 위한 자기 개선 오픈소스 모델
Ornith-1.0 - 에이전트형 코딩을 위한 자기 개선 오픈소스 모델 | GeekNews
<ul> <li><strong>Ornith-1.0</strong>은 에이전트형 코딩용 자기 개선 오픈소스 모델로, 9B Dense, 31B Dense, 35B MoE, 397B MoE 구성을 제공하며 Gemma 4와 Qwen 3.5 위에서 후훈련됨</li> <li>훈련 프레임워크는 <strong>강화학습</strong>으…
-

Import AI 460: 보상 해킹 사회, Anthropic의 RSI 데이터, RL 기반 드론 경주
Import AI 460: Reward hacking society, RSI data from Anthropic; and RL-based quadcopter racing
When will markets price the singularity?
-
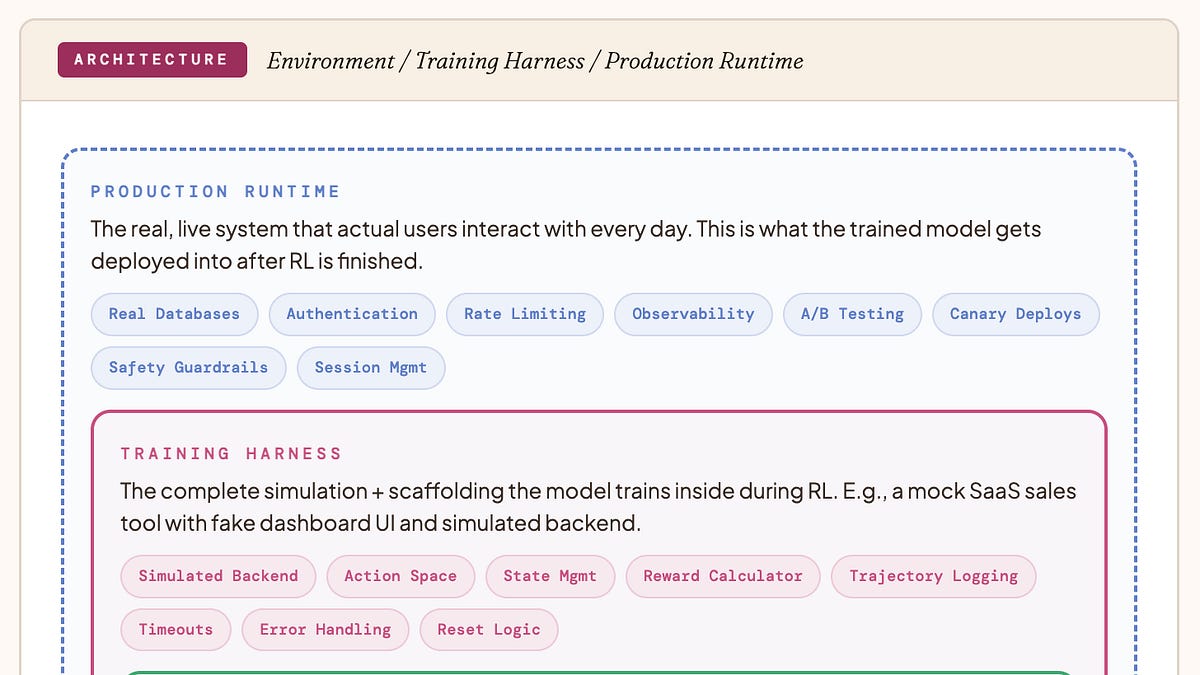
품질이 낮은 강화학습 환경 배포를 중단하는 방법 (예제 포함)
How to Stop Shipping Low-Quality RL Environments (with Examples)
Your broken harness is actively making the model worse. Here's what I keep seeing after years of eyeballing trajectories, and what you need to fix.
-

에이전트에게 컴퓨터를 제공하다 — Ivan Burazin, Daytona
Giving Agents Computers — Ivan Burazin, Daytona
We chat with Daytona's CEO about their insane 74% MoM Growth, 850K Daily Runs, Bare Metal Sandboxes, RL Evals, and the New Agent Cloud
-
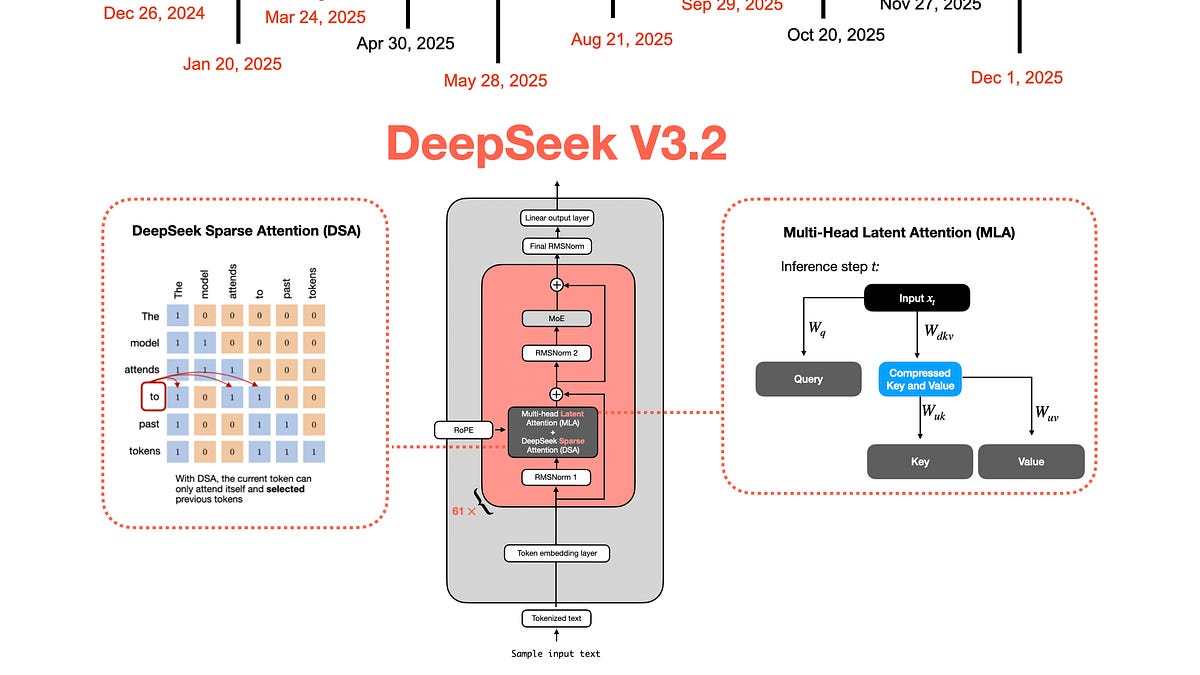
DeepSeek V3에서 V3.2로: 아키텍처, 희소 주의, 강화학습 업데이트
From DeepSeek V3 to V3.2: Architecture, Sparse Attention, and RL Updates
Understanding How DeepSeek's Flagship Open-Weight Models Evolved
-

LLM 추론을 위한 강화학습의 현황
The State of Reinforcement Learning for LLM Reasoning
Understanding GRPO and New Insights from Reasoning Model Papers